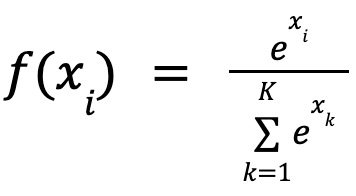Activation functions transform a linear combination of weights and biases into an output that has the ability to learn part of a complex function at each node of a network. The most basic activation function is the linear one, which is simply a weighted combination of the weights and biases fed into a given node. No matter how many layers or units present in the network, using a linear activation function at each node is nothing more than a standard linear model. However, much of the power of Neural Networks is derived from using nonlinear activation functions at each node.
Softmax is one such non-linear activation function. In the case where the output layer has multiple units, such as in multiclass problems, the Softmax activation is appropriate. The output of the softmax can be interpreted as the probability of an observation belonging to each class, where the probabilities sum up to 1.