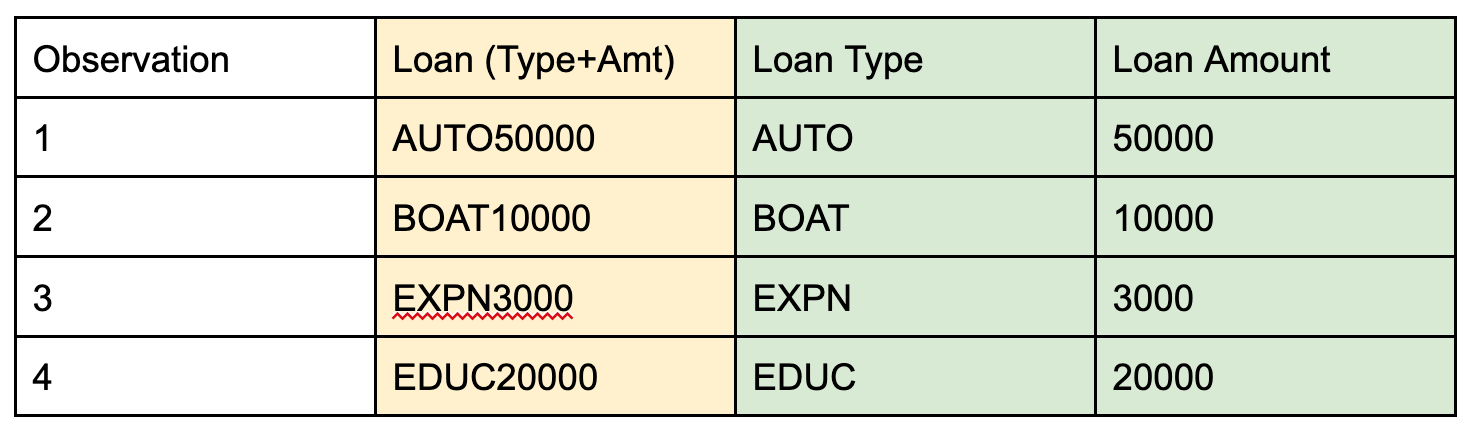
Text Feature Extraction: In some text fields, especially those that follow a consistent pattern throughout all of the observations, features can be extracted based on sub-components of the original text strings. In the example below, the original field contains a combination of the type and amount of a loan in the same string. Using text mining and regular expressions, the loan type can be found by extracting the first four characters of the string, and the amount by extracting separately everything after the fourth position. Note that one of the categorical encoding methods (Dummy Encoding, Ordinal Encoding) would need to be applied to the Loan Type field before using it in a model.