
Introduction
The key difference between cross-attention and self-attention lies in the type of input sequences they operate on and their respective purposes. While self-attention captures relationships within a single input sequence, cross-attention captures relationships between elements of two different input sequences, allowing the model to generate coherent and contextually relevant outputs.
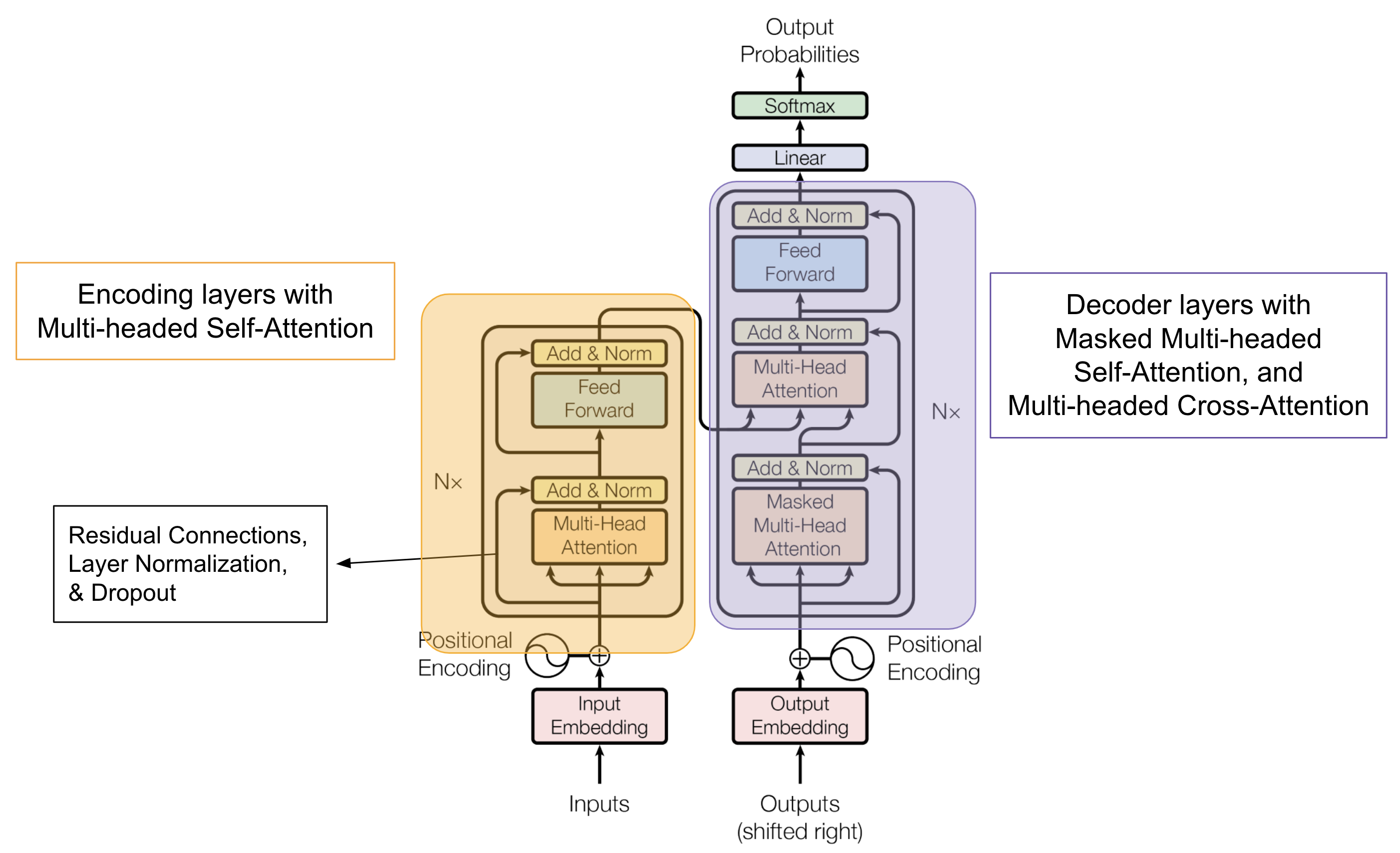
Source: “Attention is All You Need” by Vaswani et al. Enriched by AIML.com
Comparison between Self-Attention and Cross-Attention
The following table summarizes the key difference between the two:
| Self-Attention | Cross-Attention | |
| Input type | – Self-attention operates on a single input sequence. – It is typically used within the encoder layers of a Transformer model, where the input sequence is the source or input text. | – Cross-attention operates on two different input sequences: a source sequence and a target sequence. – It is typically used within the decoder layers of a Transformer model, where the source sequence is the context, and the target sequence is the sequence being generated |
| Purpose | – Self-attention captures relationships within the same input sequence. – It helps the model learn context and long-range dependencies by weighing the importance of each element within the input sequence | – Cross-attention allows the model to focus on different parts of the source sequence when generating each element of the target sequence. – It captures how elements in the source sequence relate to elements in the target sequence. This helps in generating contextually relevant outputs. |
| Usage | In the encoder of a Transformer, each word or token attends to all other words in the same sentence, learning contextual information about the entire sentence. | In machine translation, cross-attention in the decoder allows the model to look at the source sentence while generating each word in the target sentence. This helps ensure that the generated translation is coherent and contextually accurate |
| Formulation | Self-attention mechanism computes attention scores based on the Query (Q), Key (K), and Value (V) vectors derived from the same input sequence | Cross-attention also computes attention scores based on Query (Q), Key (K), and Value (V) vectors. However, in cross-attention, these vectors are derived from different sequences. Q and V from the target sequence (decoder input), and K from the source sequence (encoder output) |
Source: AIML.com Research
Illustrative Example explaining the difference
| Self-Attention | Cross-Attention | |
| Example | In machine translation, self-attention in the encoder allows the model to understand how each word in the source sentence relates to the other words in the same sentence, which is crucial for accurate translation. | In image captioning, cross-attention enables the model to attend to different regions of an image (represented as the source sequence) while generating each word of the caption (target sequence), ensuring that the caption describes the image appropriately. |
Source: AIML.com Research
Related articles:
