Related Questions:
– Explain the Transformer Architecture
– What are word embeddings? Compare Static embeddings with Contextualized embeddings
About Positional Encoding:
Positional encoding is a technique used in the Transformer architecture and other sequence-to-sequence models to provide information about the order and position of elements in an input sequence.
Left: the orange highlight blocks in the figure shows the use of Positional Encoding as input to both the Encoder and Decoder blocks of the transformer model
Right: shows an example of calculating positional encoding for input Token n with embeddings of dimension 5. The positional encodings are then added element-wise to the token embedding to generate input embedding for the model
Source: AIML.com Research
The need for Positional Encoding
In many sequence-based tasks, such as natural language processing, the order of elements in the input sequence is crucial for understanding the context and meaning. However, standard embeddings (e.g., word embeddings) don’t inherently contain information about the position of the elements. This is why positional encoding is necessary.
Unlike recurrent neural networks, the Transformer architecture processes all input tokens in parallel. Without positional information, the input tokens are treated as a bag-of-words, thereby making it difficult for the model to understand the sequential nature of the input. Therefore, positional encoding is added to the input embeddings to help the model understand the sequential structure of the data and differentiate between elements in different positions.
Specifically, in the Transformer architecture, positional encoding is added to the input embeddings before feeding the data into the encoder and decoder stacks. This allows the model to understand the sequential relationships between tokens in the input sequence and generate coherent output sequences, such as translations or text generation.
Here’s how positional encoding works:
Mathematical Representation
The formula for positional encoding is designed to provide a unique encoding for each position in the sequence. The positional encoding vector is then element-wise added to the original input embeddings to generate embeddings that include both semantic as well as positional information. The formula for positional encoding is as follows:
PE(pos, 2i) = sin(pos / 10000^(2i / d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i / d_model))
where:
– pos is the position of the element in the sequence.
– i refers to the dimension within the positional encoding vector.
– d_model is the dimension of the input embeddings.
Frequency-Based Encoding
The use of sine and cosine functions with different frequencies ensures that different positions have different representations.
– The sin terms create a cycle over positions, with a frequency that decreases exponentially. This means that the positional encoding for each dimension captures a different part of the cycle.
– The cos terms create another cycle with the same properties but with an offset phase.
The choice of 10,000 as the base for the exponential function and the use of both sine and cosine functions are empirical choices that have been found to work well in practice.
Addition to Embeddings
After calculating the positional encoding vectors using the formula above, they are element-wise added to the input embeddings. This addition combines the positional information with the semantic information contained in the embeddings.
Input_with_positional_encoding = Input_embeddings + Positional_encoding
Visualizing Positional Encoding with a change in input token position
Since, positional encoding is designed to differentiate between different positions of the input tokens, we decided to plot the following figure that shows the value of positional encoding for the first 16 input tokens with 64 dimensional embedding. As the position of input token increases, so does the number of sine and cosine cycles thereby allowing the model to understand the position and order of tokens.
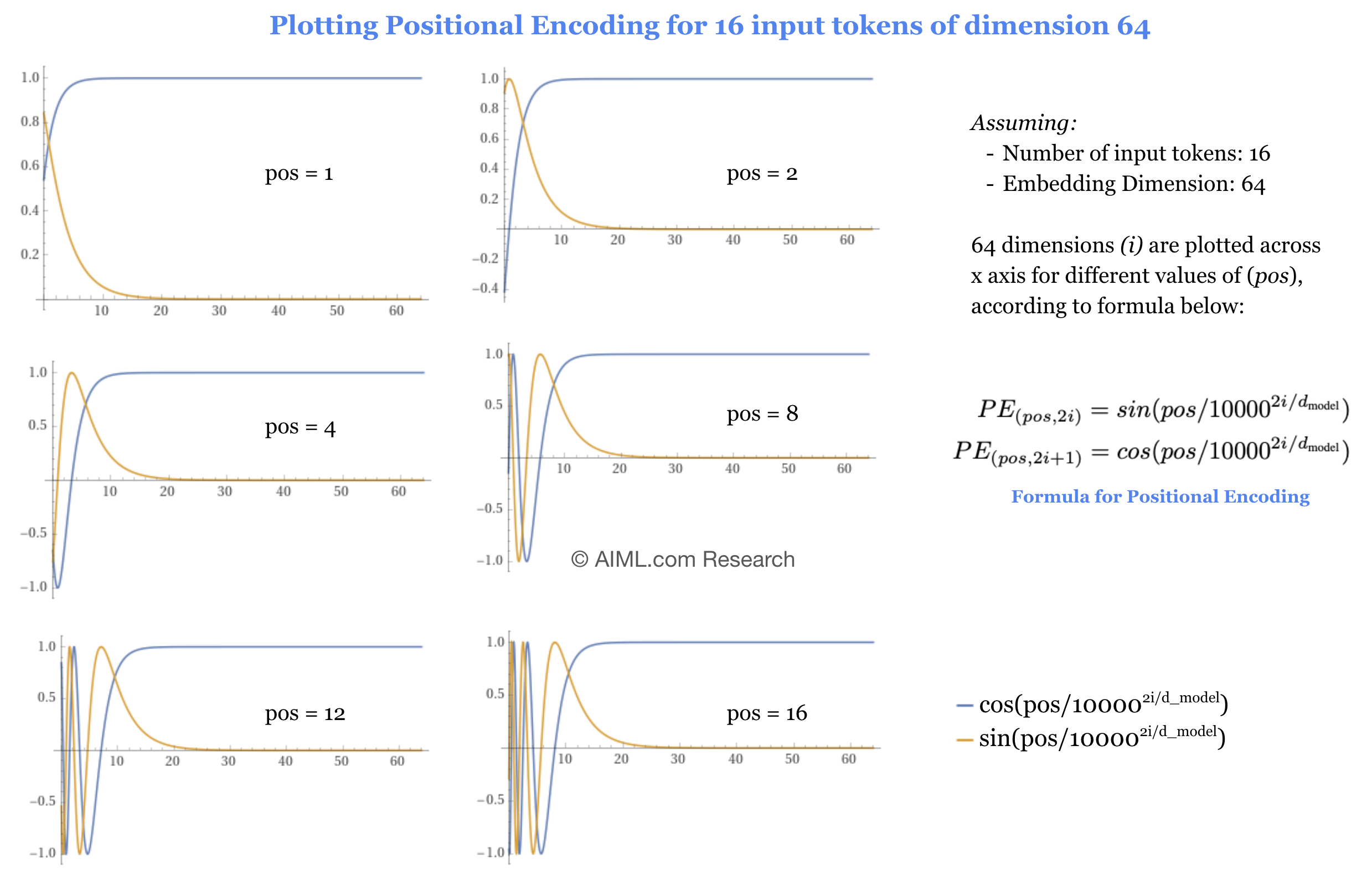
sine and cosine cycles, thereby allowing the model to understand the position and order of input sequence. Source: AIML.com Research
