Introduction
Modern AI applications ranging from interactive chatbots to advanced data analysis often rely on Transformer models for their ability to understand and generate human-like text. However, successfully harnessing these models involves navigating a range of practical considerations including:
- Model Size & Latency: How big should your model be, and how quickly must it respond?
- Data & Access: What training data is used, and do you rely on open-source or proprietary solutions?
- Ethics & Responsibility: How do you mitigate biases and avoid monopolistic control?
In this article, we examine the key factors that influence a Transformer’s performance, deployability, and ethical impact. Whether you’re a student exploring state-of-the-art NLP, a manager weighing the pros and cons of adopting AI solutions, or a practitioner seeking real-world deployment tips, you’ll learn why these considerations matter and how they shape the future of AI innovation.
If you’d like a more in-depth explanation of encoder-only, decoder-only, and seq2seq Transformer models along with their respective use cases, check out our Transformer Architectures Overview.
1. Size Matters: But How Big Is Big Enough?
The Scaling Laws
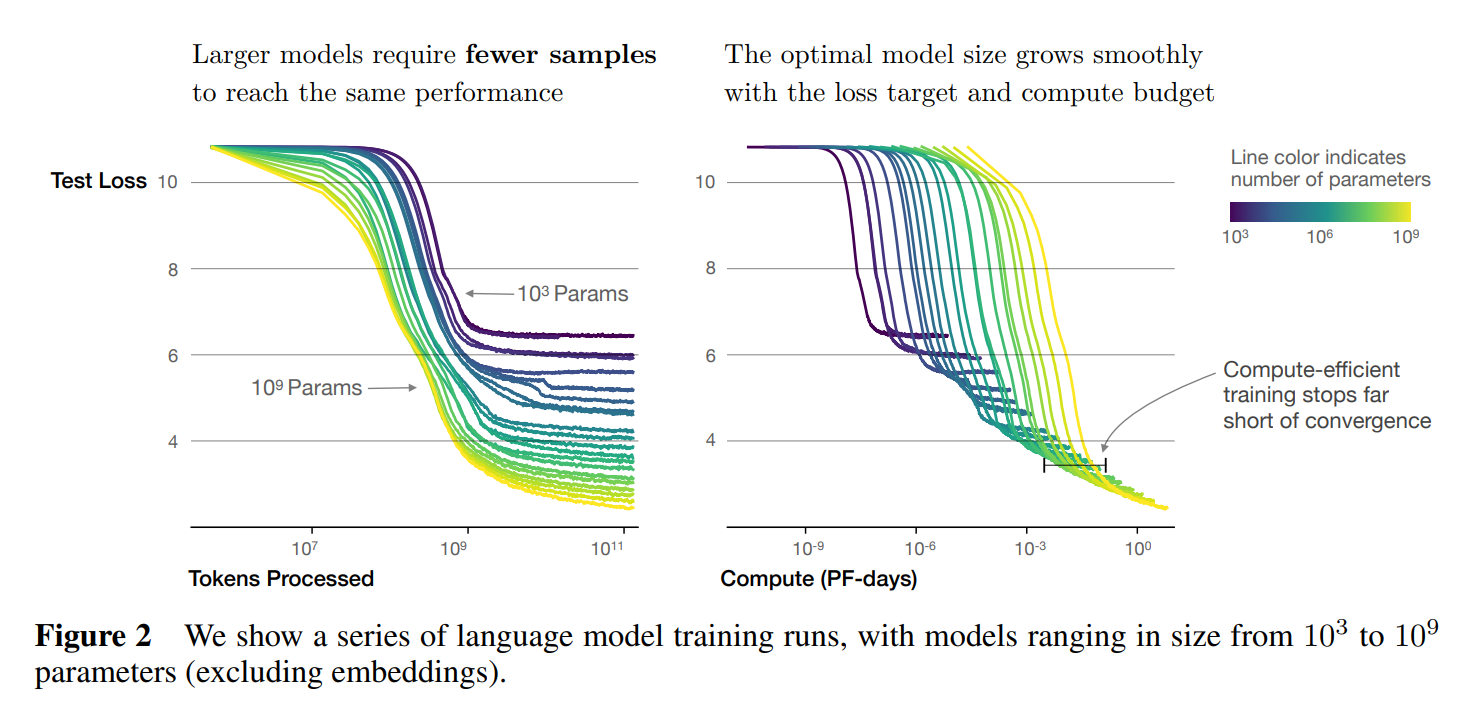
Source: Scaling Laws for Neural Language Models
When discussing large-scale Transformer models, the conversation often starts with scaling laws. One well-cited study (Kaplan et al., 2020) revealed a near-power-law relationship between model performance and model size (alongside dataset size and compute). Simply put, bigger models (measured in parameter counts) tend to yield better performance on language tasks, at least up to a point.
- GPT-2 had around 1.5 billion parameters and demonstrated impressive language generation.
- GPT-3 jumped to 175 billion parameters and made headlines with near-human-level text coherence.
- GPT-4, though not publicly detailed in exact parameter count, is rumored to be even larger and shows multi-modal capabilities.
Yet, scaling comes at a cost:
- Training such models requires massive computational resources, specialized hardware (e.g., GPUs/TPUs), and electricity.
- Inference latency skyrockets if every token generation requires computations across billions of parameters.
Thus, while scaling often boosts performance, it prompts tough questions about economic and environmental sustainability, as well as practical deployability in real-world systems that need speedy responses.
Latency and Deployability
Latency is the time it takes to generate a response. It becomes a make-or-break factor for user-facing applications. For instance, a large Transformer model might provide great accuracy or fluency, but if it takes multiple seconds to respond, it could disrupt user experience. Therefore, some organizations favor smaller “efficient” Transformers that can run on edge devices (like mobile phones) or standard cloud servers without major slowdowns.
Trade-off:
- Larger Model → better comprehension and generative ability, but higher costs and slower inference.
- Smaller Model → faster inference, cheaper deployment, but may sacrifice nuanced performance.
Modern AI strategy often involves model distillation or quantization to strike a balance between performance and speed—distilled or quantized versions of large Transformer models can run on less powerful hardware while retaining much of the original’s capability.
2. Access: Open vs. Proprietary Models

Source: Open Source vs. Proprietary Models
The Rise of Open-Source Transformers
A growing number of models are openly released to the public. Projects like Hugging Face Transformers, GPT-Neo/GPT-J from EleutherAI, BLOOM from BigScience, and LLaMA from Meta (under certain research-use conditions) exemplify this trend. Even partially restricted offerings like Claude from Anthropic demonstrate the expanding ecosystem of accessible Transformer-based models. Open-source releases enable researchers, startups, and hobbyists to build upon state-of-the-art architectures without starting from scratch.
- Pros of Open Models:
- Community collaboration and peer review.
- Transparency in architecture and training data.
- Easier domain adaptation and customization.
- Can be easily adapted to work with Proprietary data
- Better scrutiny and transparency of model’s performance
- Cons of Open Models:
- Potential risk of misuse (e.g., generating spam or malicious content).
- Ongoing maintenance and curation overhead for the open-source community.
Proprietary Giants
On the other side, many top-tier large models (like GPT-3 and GPT-4) are proprietary, hosted behind APIs by organizations such as OpenAI or large tech companies. This ensures strict control over usage, mitigates certain risks of misuse, and potentially creates revenue streams via subscription or pay-per-token plans.
- Pros of Proprietary Models:
- Typically well-maintained, with robust infrastructure and continuous updates.
- Clear usage policies and oversight to reduce harmful outputs.
- Cons of Proprietary Models:
- Vendor lock-in and limited customization.
- Potential for monopolistic practices if a small group of firms dominate the market.
- Less transparency about training data, methods, or exact parameter counts.
Monopoly Fears and Competition
As LLMs become central to AI-driven products, there are concerns that a handful of big players might dominate access and innovation. This could stifle competition and centralize AI in ways that hamper creativity and open research. Efforts by open-source communities and organizations that release free or affordable versions of advanced models aim to democratize NLP so that no single entity can corner the market.
Privacy and Proprietary Models
Privacy is a growing concern for many organizations, especially those handling sensitive or proprietary data. When relying on closed-source or proprietary language models—often accessed via remote APIs—companies may need to upload private information to a third-party service. This can raise questions about:
- Data Confidentiality: Who has access to the data once it’s uploaded?
- Compliance: Are there industry or regional regulations (e.g., GDPR, HIPAA) that restrict how data can be handled off-premises?
- Long-Term Retention: Does the service provider store your data indefinitely, and how is it used for further model training?
For these reasons, many organizations are turning to open-source models that can be self-hosted behind firewalls or on secure cloud instances. By keeping data pipelines in-house, companies maintain greater control over data governance, reduce the risk of unauthorized access, and ensure compliance with internal policies or regulatory frameworks. Although open-source approaches may require additional engineering resources and expertise, they can offer a comfortable balance between cutting-edge AI capabilities and strong privacy guarantees.
3. The Data Behind the Magic
Common Crawl, WebText, and Beyond
Behind every powerful Transformer model lies an ocean of data. Popular corpora include Common Crawl (petabytes of web-crawled text), OpenWebText (a filtered subset of Reddit-linked webpages), and vast collections of books, articles, and academic papers. The logic: the more data a model sees, the better it can learn linguistic patterns and generalize across diverse topics.
However, quantity must be balanced with quality.
- Unfiltered web data can introduce spam, hate speech, or misinformation
- Overly curated or specialized datasets can limit a model’s general knowledge
The Pile Dataset
One notable open-source compilation is The Pile by EleutherAI—a 825GB dataset drawn from 22 diverse sources, including arXiv (research papers), PubMed (medical abstracts), Gutenberg (public-domain books), and more. This infographic showcases the composition of The Pile (below, how many GB each component contributes) vividly illustrates the complexity behind large-scale dataset curation.
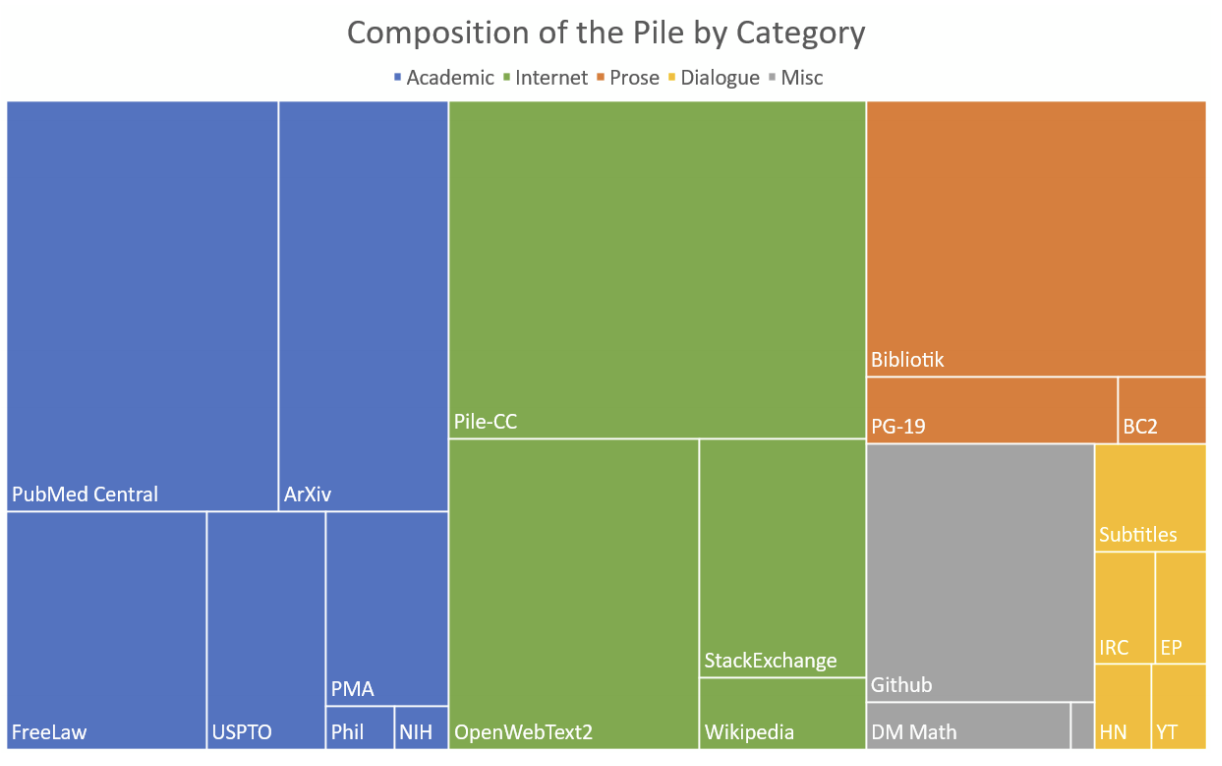
Source: The Pile
Ethics and Bias in Data Sampling
Data used to train LLMs often reflects societal biases—from stereotypes about race and gender to political biases. This is not just an abstract academic concern; biased AI can produce biased decisions, risking harm or discrimination. Effective mitigation strategies include:
- Data filtering for offensive or low-quality text.
- Algorithmic “debiasing” or fine-tuning with balanced corpora.
- Human-in-the-loop monitoring during deployment.
Still, perfect neutrality remains an elusive goal given the complexity and scale of internet data. Striking the right balance between fairness and freedom of information is a hotly debated topic in AI ethics.
Domain-Specific Corpora
In specialized fields—like medicine, law, or finance—training on general web text may not suffice. Instead, targeted corpora (medical journals, legal documents, or financial reports) are used to create or fine-tune domain-specific models. These specialized LLMs can:
- Enhance accuracy in domain-related tasks (e.g., diagnosing conditions, parsing legal clauses).
- Offer terminology and insights unique to a given industry.
- Still risk domain-specific biases or knowledge gaps if the data itself is limited or skewed.
4. Pros and Cons of Large Pretrained Transformer Models
Pros
- State-of-the-Art Performance: Thanks to massive pre-training, these models often top benchmark leaderboards and excel at tasks like question answering, summarization, and translation.
- Few-Shot Learning: Large Transformer models, particularly GPT-3 and GPT-4, can handle tasks with minimal examples, reducing data annotation costs.
- Versatility: From generating code snippets to creative writing, these models offer a broad skill set.
Cons
- High Computational Cost: Training and running these models demands expensive hardware and substantial energy consumption.
- Potential for Bias and Harmful Outputs: Unchecked, these models can reproduce offensive or incorrect content gleaned from internet data.
- Limited Interpretability: Despite advanced abilities, Transformers often behave as opaque “black boxes,” complicating debugging or accountability.
- Risk of Dependence on a Few Key Players: Centralized ownership of large models can stifle open innovation and raise prices.
5. Practical Tips: Finding the Right Transformer Recipe
Using Model Hubs
Libraries like Hugging Face Transformers provide a wide collection of pre-trained models—both large and small—complete with usage instructions, licensing details, and community-driven evaluations. If you’re just getting started or need a baseline for experimentation, these hubs are a gold mine of resources.
Balancing Quality and Latency
For production systems that require real-time interactions, consider model compression, distillation, or pruning. These techniques cut down the number of parameters (and thus inference time) while aiming to preserve most of the model’s performance.
Domain-Specific vs. General Purpose
- General-Purpose Models: Great if you need broad capabilities like summarization, Q&A, or basic translation.
- Domain-Specific Models: Superior if your use case is industry-specific, like parsing clinical trial data or generating legal briefs.
Data Quality Checks
Regardless of which pre-trained model you choose, performing data quality checks for your fine-tuning dataset is crucial. Even the best model can falter if exposed to inconsistent or poorly curated domain data.
6. A Note on Ethics and Future Directions
While we celebrate the strides made by large Transformers, it’s impossible to ignore the societal impact. Concerns around fairness, privacy, and potential misuse must guide the responsible development of these technologies. Governments and non-profit organizations are increasingly stepping in to regulate or recommend ethical guidelines for the usage of advanced AI models.
In parallel, research continues on multi-modal Transformers that integrate text, images, and even video. As these architectures expand into new domains—think medical imaging, advanced robotics, or creative content generation—the lines between disciplines will blur, and the conversation about bias, data diversity, and ethical guardrails will become even more critical.
Despite these challenges, the overarching sentiment remains positive: Transformers have catalyzed a new frontier in AI, enabling tools and applications once confined to science fiction. The key lies in balancing ambition with responsibility, ensuring open access where possible, and placing guardrails to minimize harm.
Caution: Interpretability
While Transformers and other deep learning models can achieve remarkable performance, interpretability remains a significant challenge. We often don’t fully know what patterns these models are internalizing. Models may latch onto spurious correlations without careful validation and explainable AI techniques, leading to incorrect or misleading conclusions.
This cautionary tale illustrates why human oversight, domain knowledge, and robust evaluation strategies are essential for responsible AI development.
Conclusion
From scaling laws and latency to ethics and domain adaptation, the flavors of Transformers are as diverse as the problems they aim to solve. While mega-models like GPT-3 and GPT-4 capture the spotlight, smaller or specialized models can be equally impactful within the right context. The data pipelines fueling these systems, from Common Crawl to The Pile, underline the importance of curation, transparency, and ethical considerations.
The future looks bright if we maintain a people-centric view of AI. That means encouraging open collaboration on model development and data collection, investing in research to reduce biases, and supporting robust governance to ensure no single entity corners the market. In doing so, we stand to harness the true power of Transformers—innovation that serves a broad spectrum of needs and fosters an equitable AI ecosystem.
Video Explanation
- This lecture titled “Efficient Transformers” by Song Han from MIT Han Lab delves into the efficiency in transformers, system implementation variables, and various aspects of a transformer. (Runtime: 18 mins)

- This video by Yannic Kilcher explains the research paper titled “Scaling Transformer to 1M tokens and beyond with RMT”, where he discusses one of the many scaling approaches in literature, RMT (Recurrent Memory Transformer) (Runtime: 24 mins)

Related articles:
- What are Transformers? Discuss the evolution, advantages and major breakthroughs in transformer models – AIML.com
- Explain Self-Attention, and Masked Self-Attention as used in Transformers – AIML.com
- Kaplan, J., et al. (2020). “Scaling Laws for Neural Language Models.” arXiv preprint arXiv:2001.08361.
- Brown, T. et al. (2020). “Language Models are Few-Shot Learners.” arXiv preprint arXiv:2005.14165.
- The Pile: A 825GB English Text Corpus by EleutherAI — GitHub: EleutherAI/The-Pile.
- Hugging Face Transformers library — Hugging Face.
- BLOOM: BigScience Large Open-science Open-access Multilingual Language Model — BLOOM on Hugging Face.
