
Source: Deep Solutions
Introduction
Suppose you are tasked with building a search engine. One of the most obvious challenges would be ensuring that users find relevant information even when their queries don’t match the exact wording of the documents. For instance, a user might search for “ways to stay healthy,” while the documents might contain phrases like “tips for maintaining good health.” How can we enable machines to recognize that these different phrases share similar meanings? While humans can effortlessly understand these connections, machines require a method to translate textual content into a format they can analyze. This is where embeddings come into play, offering a way to numerically represent and compare the meanings of words and phrases.
Early Solutions: One-Hot Encoding
An early attempt to represent text numerically was One-Hot Encoding. In this method, each word in a vocabulary is assigned a unique vector, where one dimension is “hot” (i.e., set to 1) and all others are 0. For example, in a vocabulary of [“red,” “blue,” “green”], the word “red” might be represented as [1, 0, 0], “blue” as [0, 1, 0], and so on.
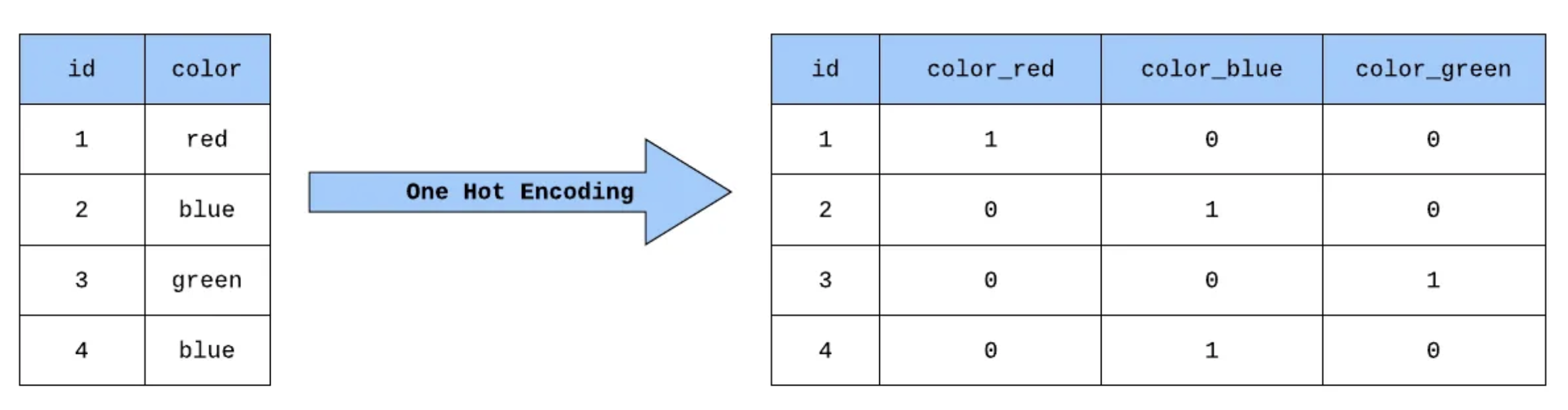
Source: Medium.com
While simple, this approach has significant limitations:
- High Dimensionality: As the vocabulary grows, the vectors become increasingly large and sparse. For reference, Oxford English dictionary has over 600k words and this doesn’t include words from the urban dictionary or people’s names
- No Semantic Information: One-hot encoding doesn’t capture relationships between words. For instance, “cat” and “dog” are semantically similar, but their vectors are entirely orthogonal.
One significant limitation of simple numeric representations like one-hot encoding is that they do not capture word meanings or relationships. It is clear that a better solution is needed.
What are Embeddings?
Embeddings are numerical representations of non-numeric data (words, documents, etc.) that capture semantic or contextual meaning. Specifically, they are dense, low-dimensional vectors that represent data (such as words) in a way that captures semantic or contextual meaning. Unlike one-hot encoding, embeddings place related data points closer together in a continuous vector space. This vector space can be visualized (see the associated Jupyter Notebook).
This mathematical relationship reflects the semantic similarity between words, making embeddings a powerful tool for many machine learning tasks.
From ranking documents in search engines to understanding the meaning of a sentence, embeddings have revolutionized how machines process data. It is difficult to pinpoint the exact subfield where embeddings originated. While Information Retrieval (IR) contributed foundational ideas like vector space representations and dimensionality reduction, embeddings in their modern form gained prominence in Natural Language Processing (NLP) with neural network-based models. Their applications span far beyond these fields, and can range from image processing to recommendation systems.
How are Embeddings Trained?
Embeddings are learned by training models on large datasets, with an objective to encode relationships and patterns within the data. A popular method for learning word embeddings is Word2Vec, introduced by Mikolov et al. (2013).
Word2Vec has two main training approaches:
- Continuous Bag of Words (CBOW): Predicts a word based on its surrounding context. For example, given “The ___ sat on the mat,” the model predicts “cat.”
- Skip-Gram: Predicts the context surrounding a given word. For example, given “cat,” the model predicts words like “sat,” “on,” and “mat.”
Both methods rely on the Distributional Hypothesis, which states that words that occur in similar contexts tend to have similar meanings. This idea is famously summarized by linguist John Rupert Firth’s famous quote: “You shall know a word by the company it keeps.” More recently, language models such as BERT can be used to generate word embeddings by leveraging their pre-training over large amounts of data.
Static vs Contextual Embeddings
Static embeddings, such as Word2Vec and GloVe, represent words as fixed vectors, meaning that each word has a single, unchanging representation regardless of its context. However, static embeddings have limitations, as they cannot capture the nuanced meanings that words may take on depending on the context. For example, the word “bank” could refer to a financial institution or the side of a river, but static embeddings would represent both meanings with the same vector.
On the other hand, contextual embeddings, as generated by models like BERT, GPT, or RoBERTa, overcome the limitations of static embeddings by taking context into account. These models use attention mechanisms to generate embeddings that are dynamic and context-sensitive, meaning the same word can have different representations based on its surrounding words. For example, in the sentence “I went to the river bank,” the embedding for “bank” would differ significantly from the embedding of “bank” in the sentence “I work at the bank.”
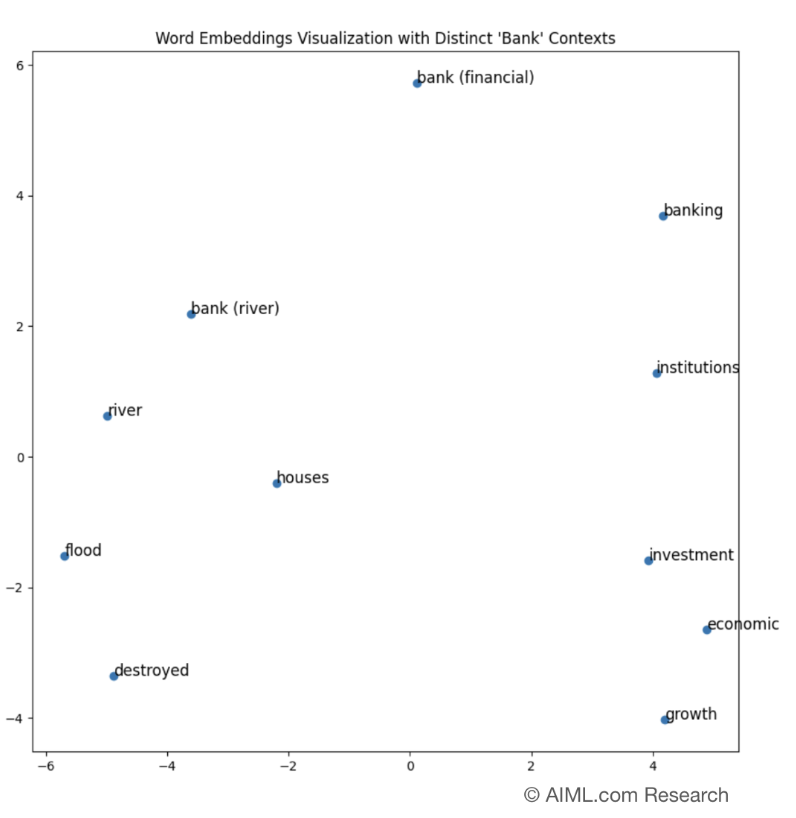
Source: AIML.com Research
Generating Sentence/Document Level Embeddings
Generating sentence or document-level embeddings involves combining individual word embeddings into one representation that captures the overall meaning of the text. For static embeddings such as Word2Vec or GloVe, a common approach is to average the word embeddings of all tokens in the text. However, this approach may lose the nuances of word relationships in the sentence. On the other hand, contextual embeddings like those from BERT or RoBERTa offer a more precise method by leveraging the special [CLS] token, which represents the beginning of the sentence.This makes contextual embeddings more powerful for capturing sentence-level meaning, as they incorporate context-dependent nuances that static embeddings cannot.
Challenges
A significant concern and critique is that embeddings can inadvertently encode and amplify societal biases present in the training data. For example, the paper “Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings,” Bolukbasi et al. (2016) highlighted how embeddings often reflect gender stereotypes, associating professions like “programmer” with men and roles like “homemaker” with women.

Title: Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings
Source: UCLA
Addressing such biases requires careful dataset curation and debiasing techniques to ensure that embeddings promote fairness and inclusivity.
Conclusion
Embeddings solve a critical problem in machine learning: representing complex, non-numeric data in a way that captures meaning and relationships. They are essential in modern NLP, powering applications from search engines to foundation models.
Videos for Further Exploration
- The IBM Technology team provides an introduction of word embeddings, including their applications, methods, and models (Runtime: 9 mins)

- In this video, Josh Starmer provides a great explanation of Word2Vec, a popular method for learning word embeddings (Runtime: 16 mins)

- New embedding model: Contextual Document Embeddings gives a short summary of what Contextual Embeddings are and how they are generated. (Runtime: 3 mins)

