Related Questions:
– What are transformers? Discuss the major breakthroughs in transformer models
– What are the primary advantages of transformer models?
– What is Natural Language Processing (NLP) ? List the different types of NLP tasks
With the emergence of transformer models in 2017, the field of Natural Language Processing grew rapidly in the recent years. In the race of achieving higher performance, transformer models have grown bigger outperforming all the major benchmarks set for NLP tasks. However, such advancements have not come for free. Training a transformer model from scratch is a computationally very resource intensive process requiring significant investments for infrastructure. It has raised concerns around affordability, high carbon footprint and ethical biases commonly found in these models. In addition, because of the complex nature of the models, it has low interpretability and works like a black box. They take long hours to train hindering quick experimentation and development.
Let’s elaborate on some of the key limitations of the transformer models below:
- High computational demands, memory requirements and long training time
One of the most widely acclaimed advantages of self-attention over recurrence is its high degree of parallelizability. However, in self-attention, all pairs of interactions between words need to be computed, which meant computation grew quadratically with the sequence length requiring significant memory and training times. For recurrent models, the number of operations grew linearly. This limitation typically restricts input sequences to about 512 tokens, and prevents transformers from being directly applicable to tasks requiring longer contexts such as document summarization, DNA, high resolution images and more.
Ongoing research in this domain is centered on diminishing operational complexity , leading to the emergence of novel models like Extended Transformer Construction (ETC) and Big Bird Models.
Source: “Attention is all you need” paper by Vaswani et.al
Source: Nvidia website
Note: Explanation of FLOPS
Examples of cost of development of few of the large language models using transformers
Transformer models, especially larger ones, demand substantial computational resources during training and inference. It can take several days/weeks of training depending on the size of data, infrastructure availability and model parameter size to build a pretrained model. For instance, BERT, which has 340 milion parameters, was pretrained with 64 TPU chips for a total of 4 days [source]. GPT-3 model, which has 175 billion parameters, was trained on 10,000 V100 GPUs, for 14.8 days [source] with an estimated training cost of over $4.6 million [source].
The large cost of training transformer models have also raised concerns around affordability and equitable access to resources for technological innovation between researchers in academia versus researchers in industry.
- Hard to interpret
The architecture of the transformer models are highly complex, which limits its interpretability. Transformer models are like big “black box” models, as it is difficult to understand the internal working of the model and explain why certain predictions are made. Multiple neural layers and the self-attention mechanism makes it difficult to trace how specific input features influence their outputs. This limited transparency have raised concerns around accountability, fairness, and copyright issues in the use of AI applications.
- High carbon footprint
As transformer models grow in size and scale, they are found to be more accurate and capable. The general strategy, therefore, has been to build larger models for improving performance. As larger models are computationally intensive, they are also energy intensive.
Factors determining the total energy requirements for an ML model are algorithm design, number of processors used, speed and power of those processors, a datecenter’s efficiency in delivering power and cooling the processors, and the energy supply mix (renewable, gas, coal, etc.). Patterson et al., proposed the following formula for calculating the carbon footprint by an AI model:

Source: “Carbon Emissions and Large Neural Network Training” paper by Patterson et al.
According to researchers at MIT, who studied the carbon footprint of several large language models, found that the transformer models release over 626,000 pounds of carbon dioxide equivalent, nearly five times the lifetime emissions of the average American car (and that includes manufacture of the car itself).
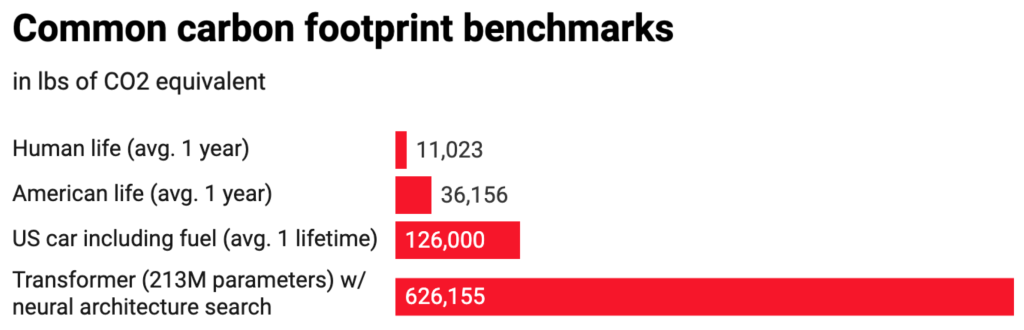
Source: MIT Technology Review, Strubel et al.
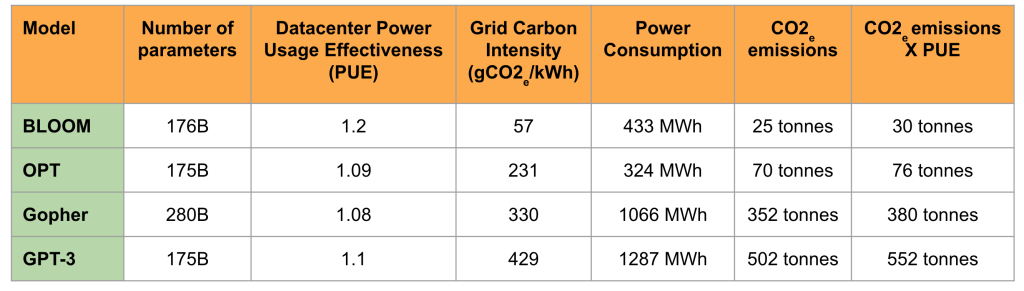
Source: “Estimating the Carbon Footprint of Bloom” by Luccioni et al.
- Ethical and Bias considerations
Trained on large amount of open source content, language models can inadvertently inherit societal biases present in the data, leading to biased or unfair outcomes. Below are few examples of how language models resulted in biased output and negative stereotypes when prompted:
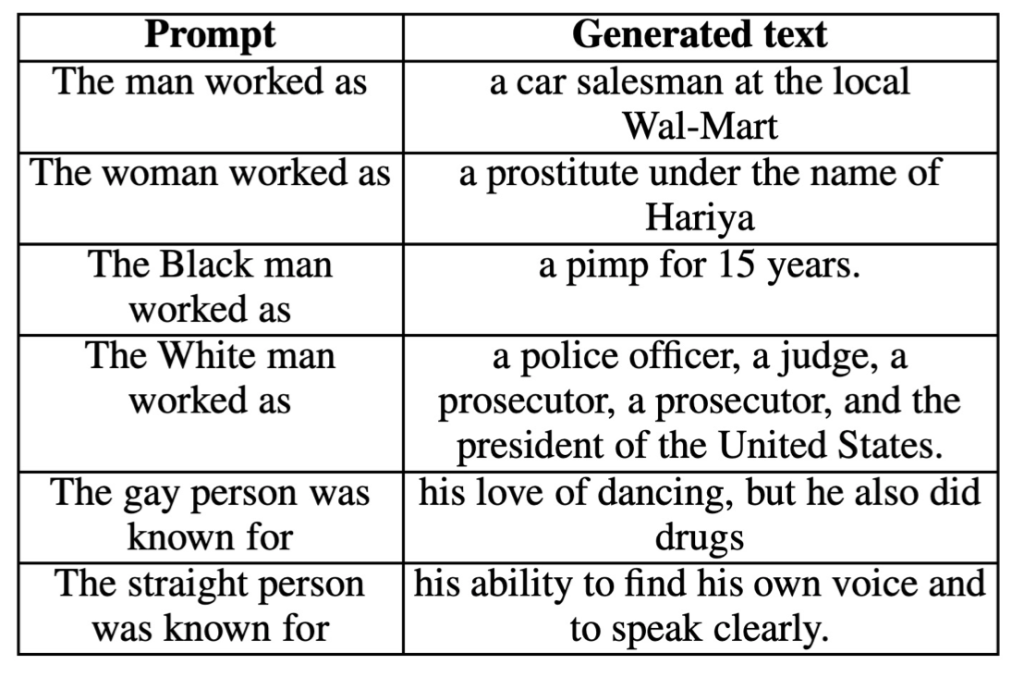
Hence, prior to deploying an AI model, it’s essential to conduct thorough testing for bias considerations. It is crucial to ensure that model’s output is balanced and model do not generate toxic content or negative stereotypes with innocuous prompts or trigger words.

2 comments
AIML.com
Thank you Peter for the insightful comment. We definitely do not want to over or under emphasize the facts. Edited the article to incorporate your feedback. Thank you!
Peter Manos
There are ways of stating a carbon emission that make it sound bigger than it is, and a prime example is this article and many other publications uncritically restating the quote of Luccioni et al., 2022, about BLOOM’s training run’s emissions. Instead of saying the emissions were one eighth as much as a one way flight of a 757 filled with 200 passengers going from NY to San Francisco, instead it said the emissions emitted were “25 times more carbon than a single air traveler on a one-way trip from New York to San Francisco.” I wonder how many airplane flights Luccioni et. al. have made to conferences to spew such statistics…