Related Questions:
– Explain the basic architecture and training process of a Neural Network model
– What is an activation function? Discuss the different types and their pros and cons
Hyper-parameters in a Neural Network Model
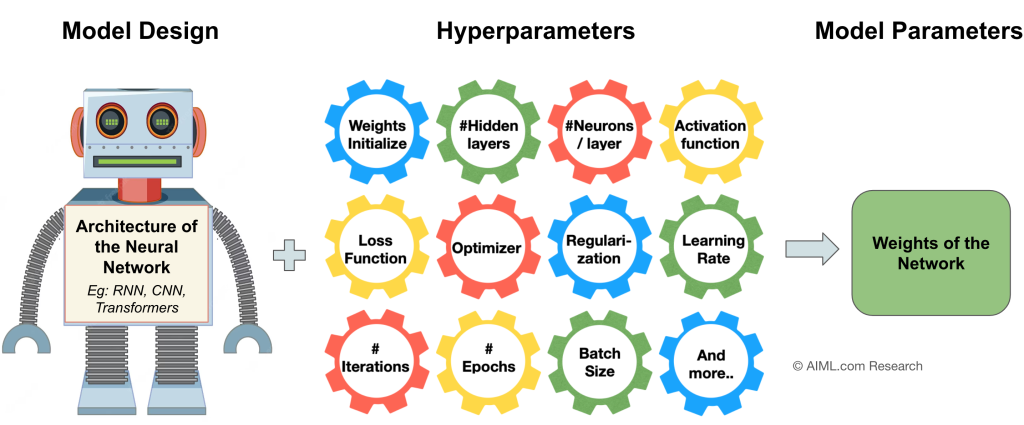
Source: AIML.com Research
Hyperparameters are the configuration settings of a neural network that are set before the training process begins. These parameters are not learned during training, instead they influence how the model learns and generalizes from the data. Here are some key hyperparameters of a neural network model:
- Weight initialization at the beginning of the network training. This can impact how quickly the model converges. Eg: random initialization, Xavier/Glorot initialization, and He initialization
- Number of hidden layers, also known as depth of the network, impact the learning capacity and generalization ability of the network
- Number of neurons per layer impacts the network’s capacity to capture complex patterns. Larger layers can capture more intricate features but might also lead to overfitting
- Activation function introduces non-linearity into the model, allowing it to capture complex relationships in the data. Eg: ReLU (Rectified Linear Unit), tanh, Leaky ReLU

- Loss function quantifies the difference between the predicted and actual values. Neural Network training aims to minimize the loss function. The choice of loss function depends on the type of problem you’re solving. Eg: Mean Squared Error (MSE), Huber Loss for regression tasks, and Cross-entropy for classification
- Optimization algorithm determines how the model’s weights are updated during training. Eg: Stochastic Gradient Descent (SGD), Adam, RMSProp
- Learning Rate determines the step size taken during weight updates in the optimization process. A larger learning rate can lead to faster convergence but might risk overshooting the optimal parameters. A smaller learning rate can lead to slower convergence but with more stable adjustments. Some of the popular learning rate values used are 0.1, 0.01, 0.001
It’s common to start with a larger learning rate and then decrease it gradually during training using techniques like learning rate decay. The idea behind learning rate decay is that at the beginning of training, when the model’s parameters are far from the optimal values, using a larger learning rate can help the model converge faster. However, as training progresses and the parameters get closer to the optimal values, a smaller learning rate might be more appropriate to ensure that the model converges accurately and doesn’t overshoot the optimal solution. - Batch Size is the number of training examples used in a single iteration of gradient descent. Typical values for batch size are 16, 32, 64, 128, 256, 512 and 1024.
- Epochs is the number of times the entire training dataset is passed through the network during training. Eg: 1, 10, 50, 100
- Number of iterations: An iteration refers to one update of the model’s parameters based on a batch of training examples. During each iteration, a mini-batch of data (subset of the training data) is used to compute gradients and update the model’s weights and bias parameters. The total number of iterations can be calculated using the following formula:
No. of iterations = (Total training examples / Batch size) * Total epochs - Regularization Techniques are used to prevent overfitting, or the problems of dead neurons. Some of the common regularization methods are Dropout, L1 (Lasso) / L2 (Ridge), Batch normalization, and Early Stopping.
Few practical examples for hyper-parameter values:
- Hyperparameters for training a Deep Neural Network (DNN)

Source: DNN-Assisted Cooperative Localization in Vehicular Networks paper published by School of Electrical Engineering, Korea University
- Hyperparameters for training the GPT series (large language models)
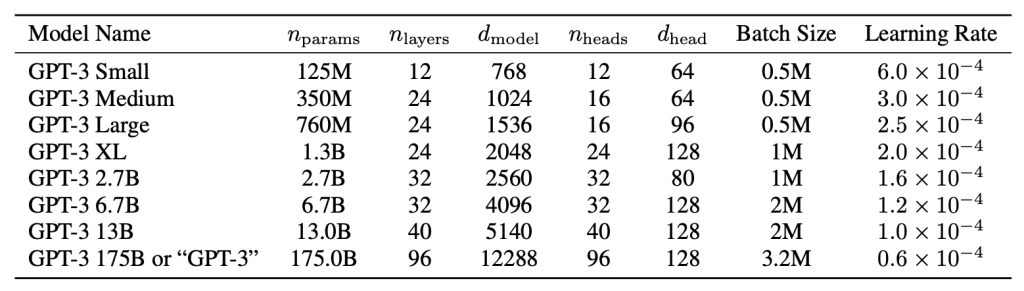
Source: GPT-3 paper: Language Models are Few-Shot Learners
Video Explanation
- In the “Neural Networks Hyperparameters explained” video, Misra Turp draws out the neural network structure and clearly explains the hyperparameters used in Neural Network training at different parts of the network (Runtime: 7 mins)

- In the “Hyperparameter Tuning” video, Misra Turp goes a step further into the hyperparameter concept of Neural Network and talks about different methods of Hyperparameter tuning including Grid search, Random search, Manually zooming in and some other sophisticated techniques such as Bayesian search, gradient-based search and evolutionary algorithms. (Runtime: 10 mins)

