Related Questions:
– What is an activation function? Discuss the different types and their pros and cons
– What is the vanishing and exploding gradient problem, and how are they typically addressed?
– What is Rectified Linear Unit (ReLU) activation function? Discuss its pros and cons
In the context of neural networks, saturation refers to a situation where the output of an activation function or neuron becomes very close to the function’s minimum or maximum value (asymptotic ends), and small changes in the input have little to no effect on the output. This limits the information propagated to the next layer. For example: In the sigmoid activation function, as the input becomes extremely positive or negative, the output approaches 1 or 0, respectively, and the gradient (derivative) of the function becomes very close to zero. In the hyperbolic tangent (tanh) activation function, a similar saturation occurs for very large positive or negative inputs, resulting in output values close to 1 or -1.
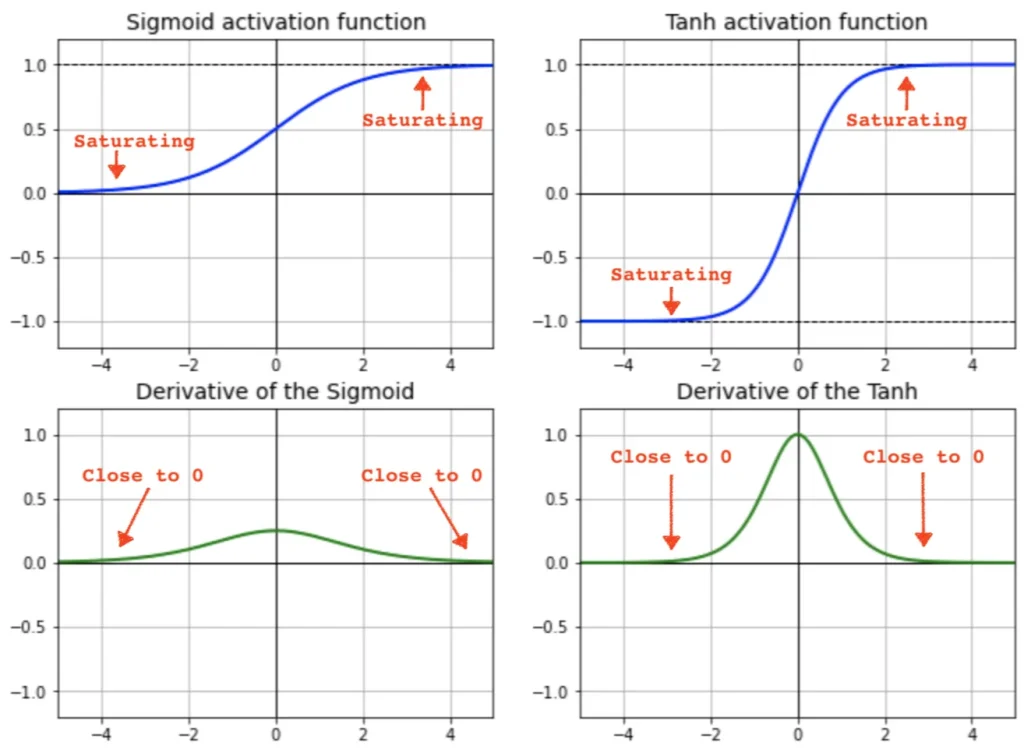
Source: “Why ReLU in Deep Learning” article by B.Chen
Saturation becomes a critical issue in neural network training as it leads to the vanishing gradient problem, limiting the model’s information capacity and its ability to learn complex patterns in the data. When a unit is saturated, small changes to its incoming weights will hardly impact the unit’s output. Consequently, a weight optimization training algorithm will face difficulty in determining whether this weight change positively or negatively affected the neural network’s performance. The training algorithm would ultimately reach a standstill, preventing any further learning from taking place.

Source: “Measuring Saturation in Neural Networks” conference paper, IEEE
To address saturation-related issues, many modern neural networks use activation functions like Rectified Linear Unit (ReLU) and its variants, which do not saturate for positive inputs and allow gradients to flow more freely during training. Additionally, techniques like batch normalization and skip connections have been introduced to mitigate saturation-related problems in deep networks.
Video Explanation
- In this video, Misra Turp talks about using non saturating activation functions as a solution to vanishing gradient problem. She explains the behavior of different activation function with regards to saturation and suggests how to go about choosing activation function for your neural network

