Related Questions:
– What is a Perceptron? What is the role of bias in a perceptron (or neuron)?
– What is Deep Learning? Discuss its key characteristics, working and applications
– Explain the basic architecture and training process of a Neural Network model
Introduction
A Multilayer Perceptron (MLP) is one of the simplest and most common neural network architectures used in machine learning. It is a feedforward artificial neural network consisting of multiple layers of interconnected neurons, including an input layer, one or more hidden layers, and an output layer. In the context of Deep Learning, a Perceptron is usually referred to as a neuron, and a Multi- Layer Perceptron structure is referred to as a Neural Network.
MLPs are capable of learning complex and non-linear relationships in data (as shown in pic below), especially when they have multiple hidden layers and non-linear activation functions.
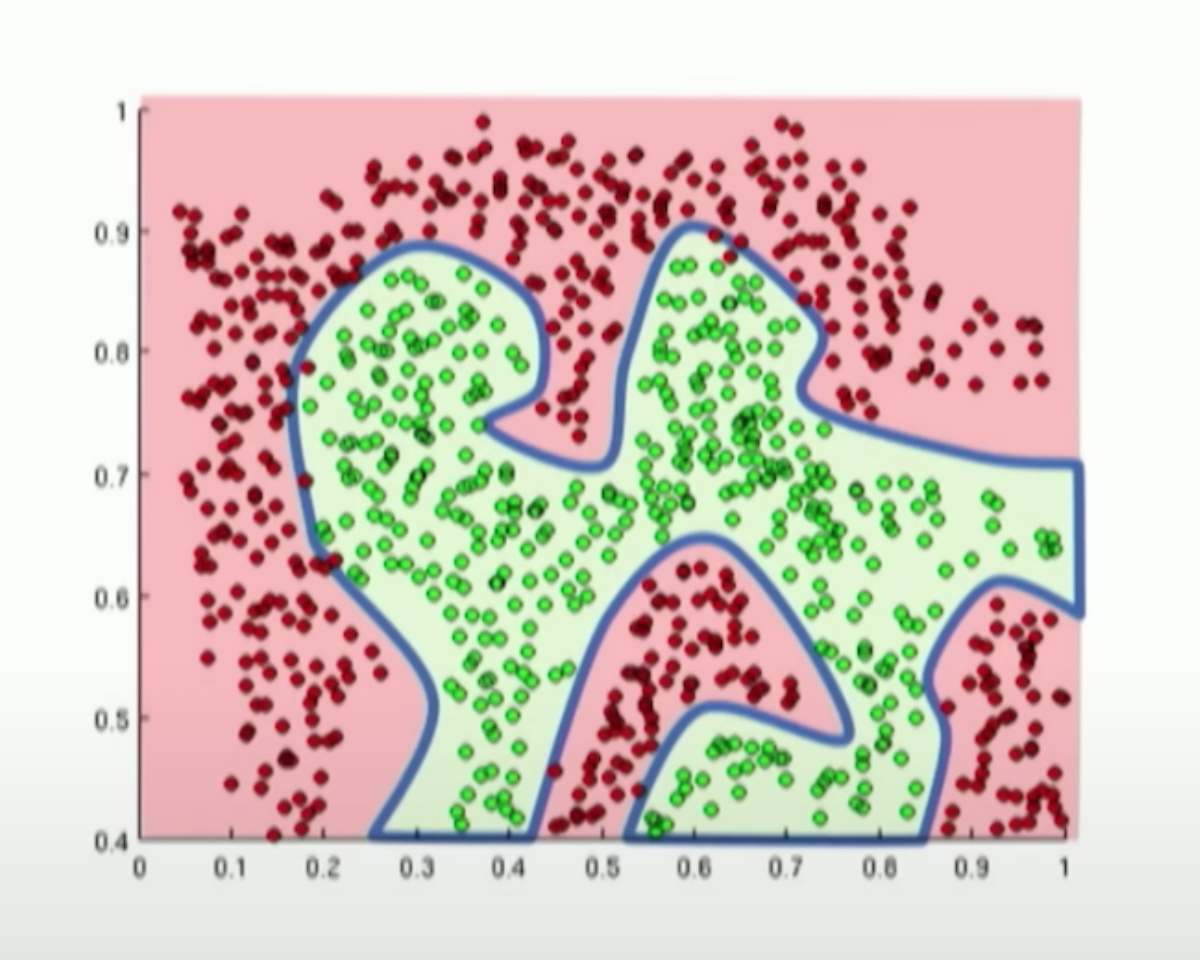
Title: Learning of a complex pattern by Multilayer perceptron
Source: MIT Deep Learning Course
Key components and working of a Multilayer Perceptron
A Multi-Layer Perceptron learns to map inputs to outputs through a process of forward propagation and backpropagation, adjusting its weights and biases based on the error between its predictions and the actual data. This learning process allows it to capture and model complex relationships in the data. Presented below are the key characteristics and training process of an MLP model:
- Input layer: The process starts with the input layer, which receives the input data. Each neuron in this layer represents a feature of the input data.
- Weighted Connections and Biases
Connections between neurons have associated weights, which are learned during the training process. These weights determine the strength of the connections and play a crucial role in the networkʼs ability to capture patterns in the data. In addition, each neuron, in the hidden and output layers has an associated bias term, which allows for fine-tuning and shifting the activation functionʼs threshold. These weights and biases are parameters that the neural network learns during training.
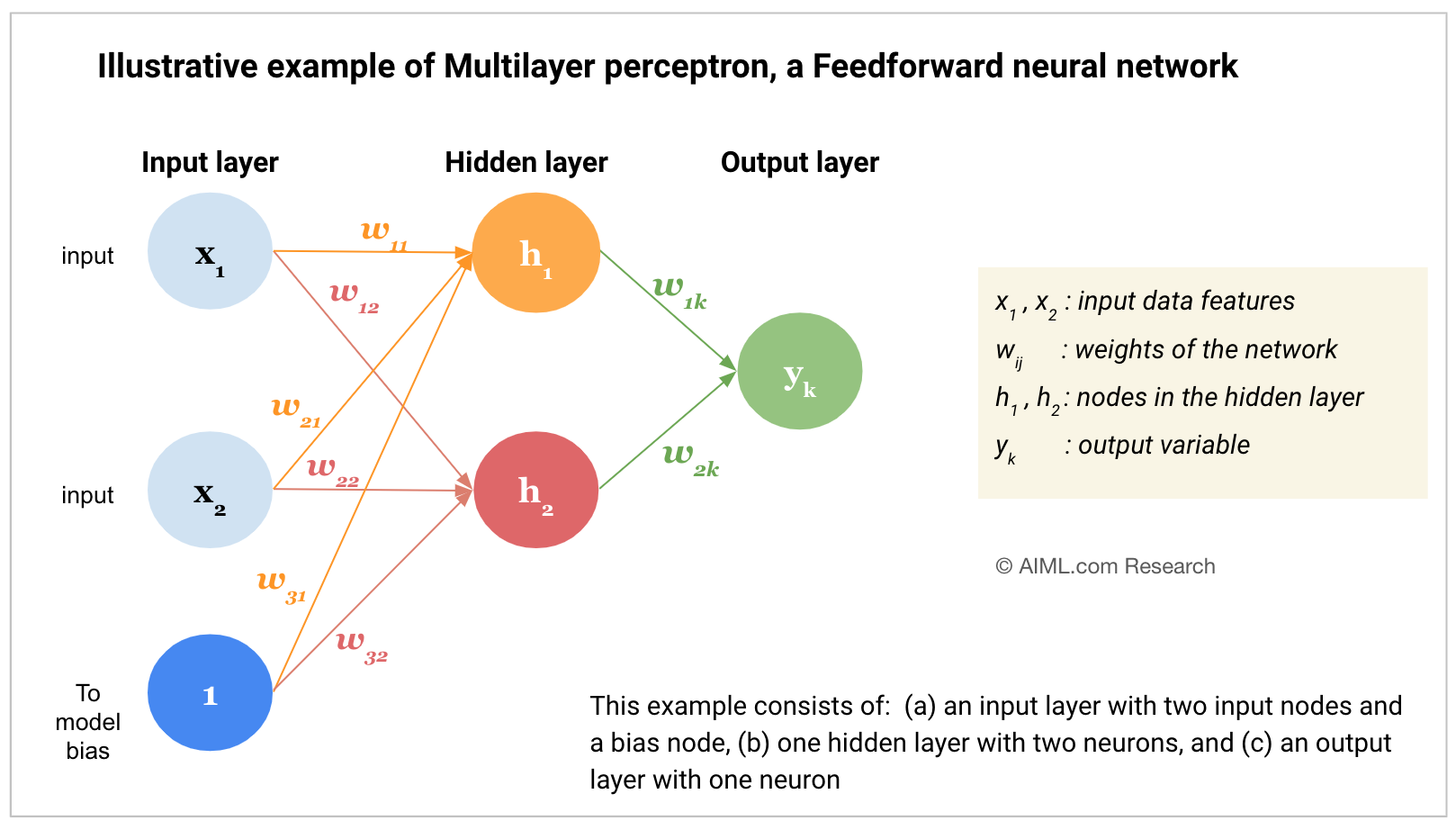
Source: AIML.com Research
- Hidden Layers: After the input layer, there are one or more hidden layers. The neurons in these layers perform computations on the inputs. The output of each neuron is calculated by applying a weighted sum of its inputs (from the previous layer), adding a bias, and then passing this sum through an activation function.
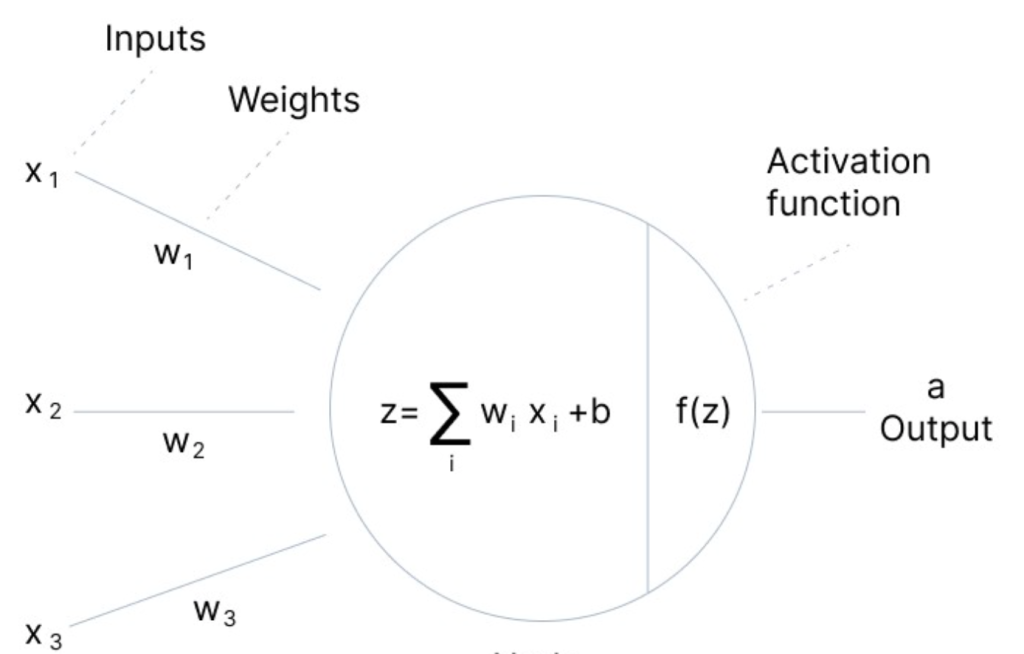
- Activation Functions
The activation function is crucial as it introduces non-linearity into the model, allowing it to learn more complex patterns. Common activation functions include sigmoid, tanh, and ReLU (Rectified Linear Unit).
- Forward Propagation
The process from the input layer through the hidden layers to the output layer is called forward propagation. In each layer, the aforementioned steps (weighted sum, bias addition, activation function) are applied to compute the layer’s output. In an MLP, information flows in one direction, from the input layer through the hidden layers to the output layer. There are no feedback loops or recurrent connections, hence the name feedforward architecture.
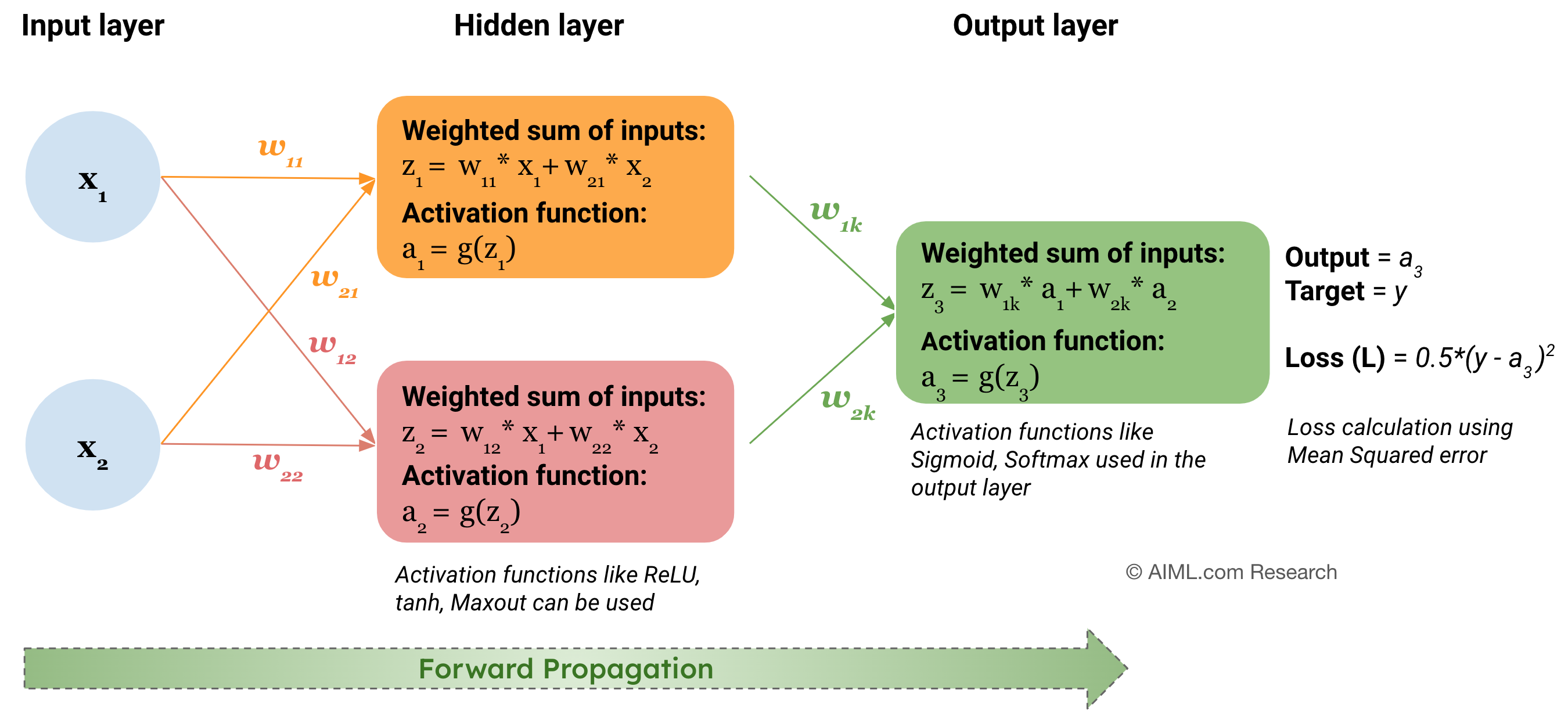
Note: bias term is not shown in the above diagram
- Output layer
The final layer is the output layer. In a classification task, this layer often uses a softmax function if the task is multi-class classification, or a sigmoid function for binary classification. For regression tasks, no activation function might be applied in the output layer.
- Backpropagation and Learning: Once a forward pass through the network is completed, the output is compared to the true value to calculate the error. The error is then propagated back through the network (backpropagation), adjusting the weights and biases to minimize the error. Backpropagation is typically done using optimization algorithms, such as stochastic gradient descent (SGD) and its variants.

- Iteration and Convergence: The process of forward propagation, error calculation, backpropagation, and parameter update is repeated for many iterations over the training data. Gradually, the network learns to reduce the error, and the weights and biases converge to values that make the network capable of making accurate predictions or approximations.
Applications of Multilayer perceptron
MLPs are universal function approximators, i.e. they are capable of approximating any continuous function to a desired level of accuracy, given enough hidden neurons and appropriate training. This property makes them powerful tools for solving a wide range of problems including:
- Classication such as sentiment analysis, fraud detection
- Regression such as score estimation
- NLP tasks such as machine translation
- Anomaly Detection
- Speech Recognition in virtual assistant systems such as Siri, Alexa
- Computer Vision for object identification, image segmentation
- Data analytics and data visualization
Video explanation
- In this set of two videos (Runtime: 15 mins and 21 mins respectively) by Coding Train, Daniel Shiman provides a good build up of why we need Multilayer perceptron (consisting of multiple neurons and layers) as compared to a single perceptron (a neuron) to solve complex non-linear problems. You may choose to watch just the first video to gain a good understanding or continue with the second part for a deeper insight.

