Source: KDB.ai
Introduction
Imagine categorizing news articles. Two articles might use different words but discuss the same topic:
Article 1: “Apple announces its latest iPhone with improved battery life.”
Article 2: “Samsung’s new smartphone offers a longer-lasting battery.”
A keyword-based system might not see the connection, but by converting text into vectors (numerical representations via embeddings), we can measure their similarity. If their vectors are close together, they likely discuss the same topic.
Now compare:
Article 3: “A new café opens downtown, offering organic coffee and fresh pastries.”
This article is unrelated, so its vector would be farther away in numerical space.
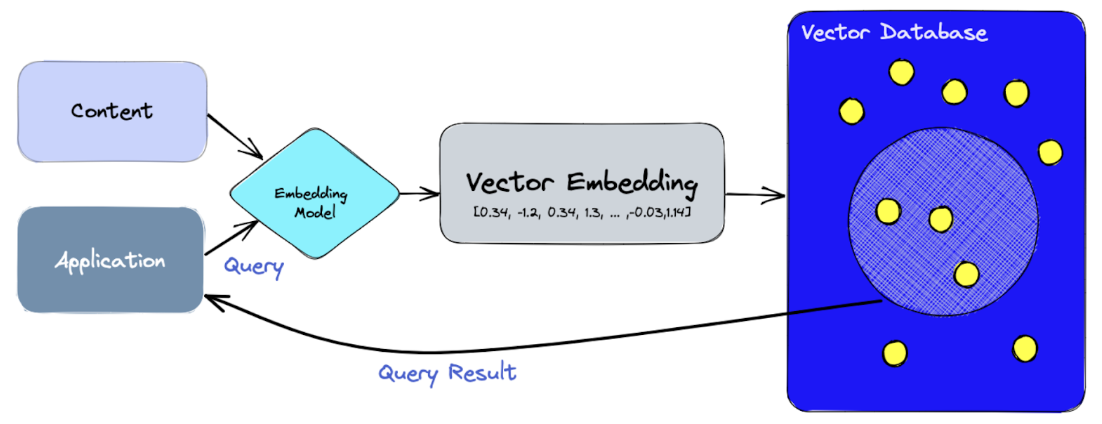
This is because a vector is an ordered list of numbers that captures relationships between concepts. Similar texts have vectors that are mathematically proximal, while unrelated ones are far apart. AI systems compute these similarities using metrics like cosine similarity or Euclidean distance to find related content efficiently.
However, searching for similar articles in a collection of thousands or even millions of documents without optimization is extremely computationally inefficient. A vanilla approach would involve comparing a query’s vector to every stored vector individually, calculating similarity scores for each one. This brute-force method, known as exhaustive search, becomes impractical as datasets grow.
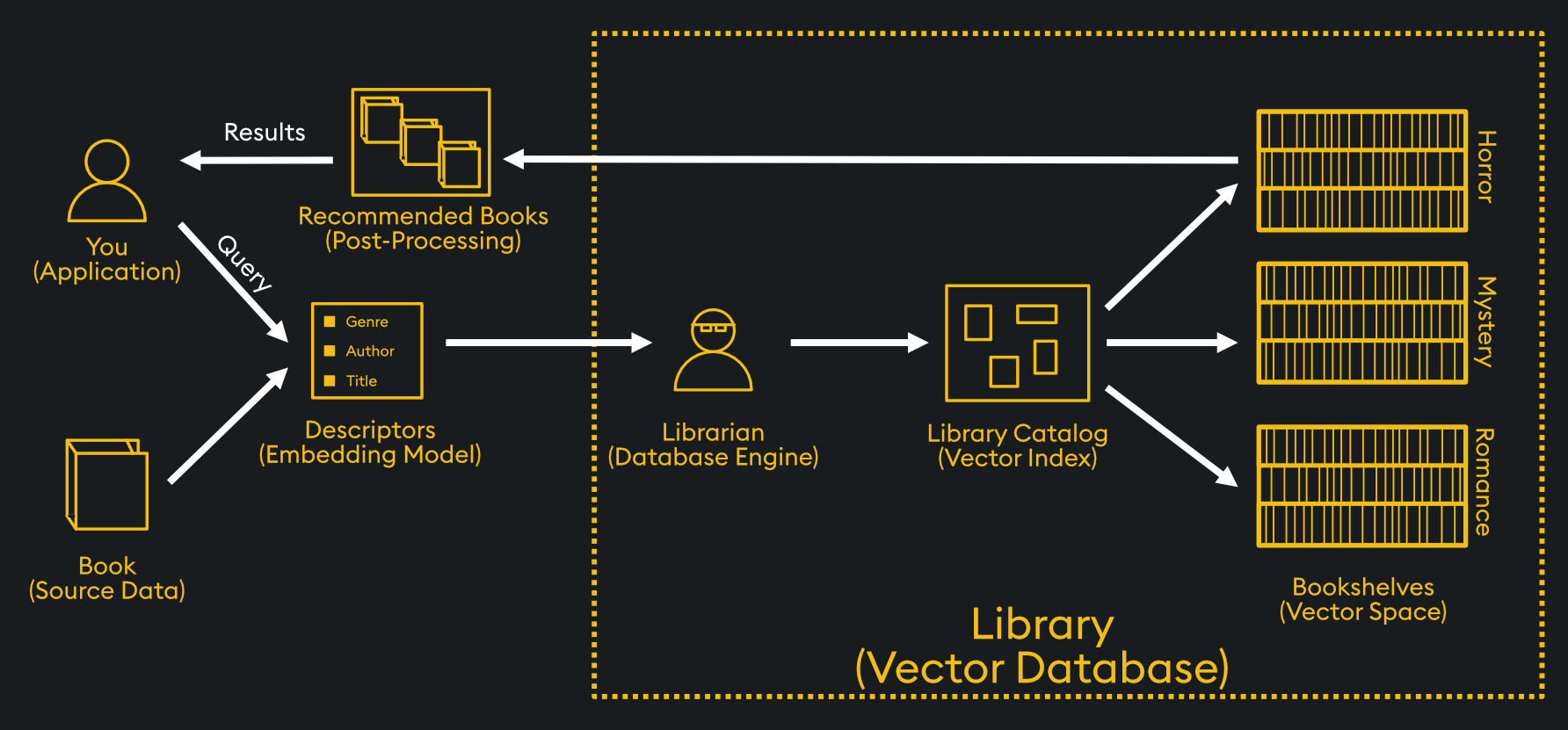
Handling large numbers of vectors requires a Vector Database (VectorDB), a system optimized for storing, indexing, and retrieving high-dimensional vectors. VectorDBs power search engines, recommendation systems, and Retrieval-Augmented Generation (RAG) by enabling fast, similarity-based lookups to enhance AI-driven responses.
Source: Capella
How do Vector Databases Work?
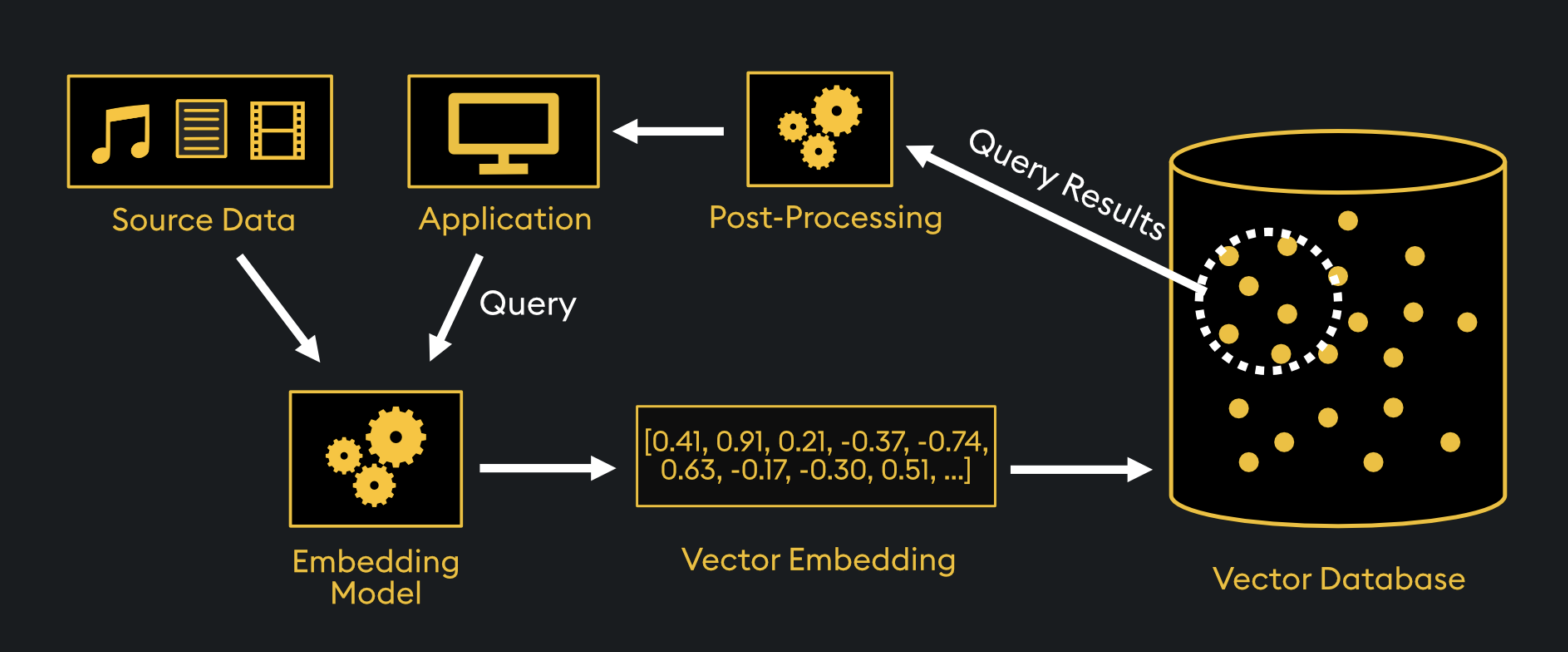
Vector Databases store high-dimensional vector embeddings and use specialized indexing techniques to enable fast similarity searches without scanning every entry. Instead of linear search, they employ structures like Inverted File Index (IVF), which clusters similar vectors to narrow down search space. Alternatively, Hierarchical Navigable Small World (HNSW) graphs create connected networks of similar vectors for quick lookups.
Source: KDB.ai
These methods significantly reduce search time by allowing the database to narrow the search space before performing similarity comparisons. When a query is made, the VectorDB first narrows the search space. This is done either by identifying the most relevant cluster (clustering-based methods) or by traversing a graph structure (graph-based methods). It then retrieves the closest matches using similarity metrics such as cosine similarity or Euclidean distance. This approach enables efficient similarity search and allows VectorDBs to power applications such as RAG, recommendation systems, and semantic search at scale.
Comparisons of Existing Vector Databases
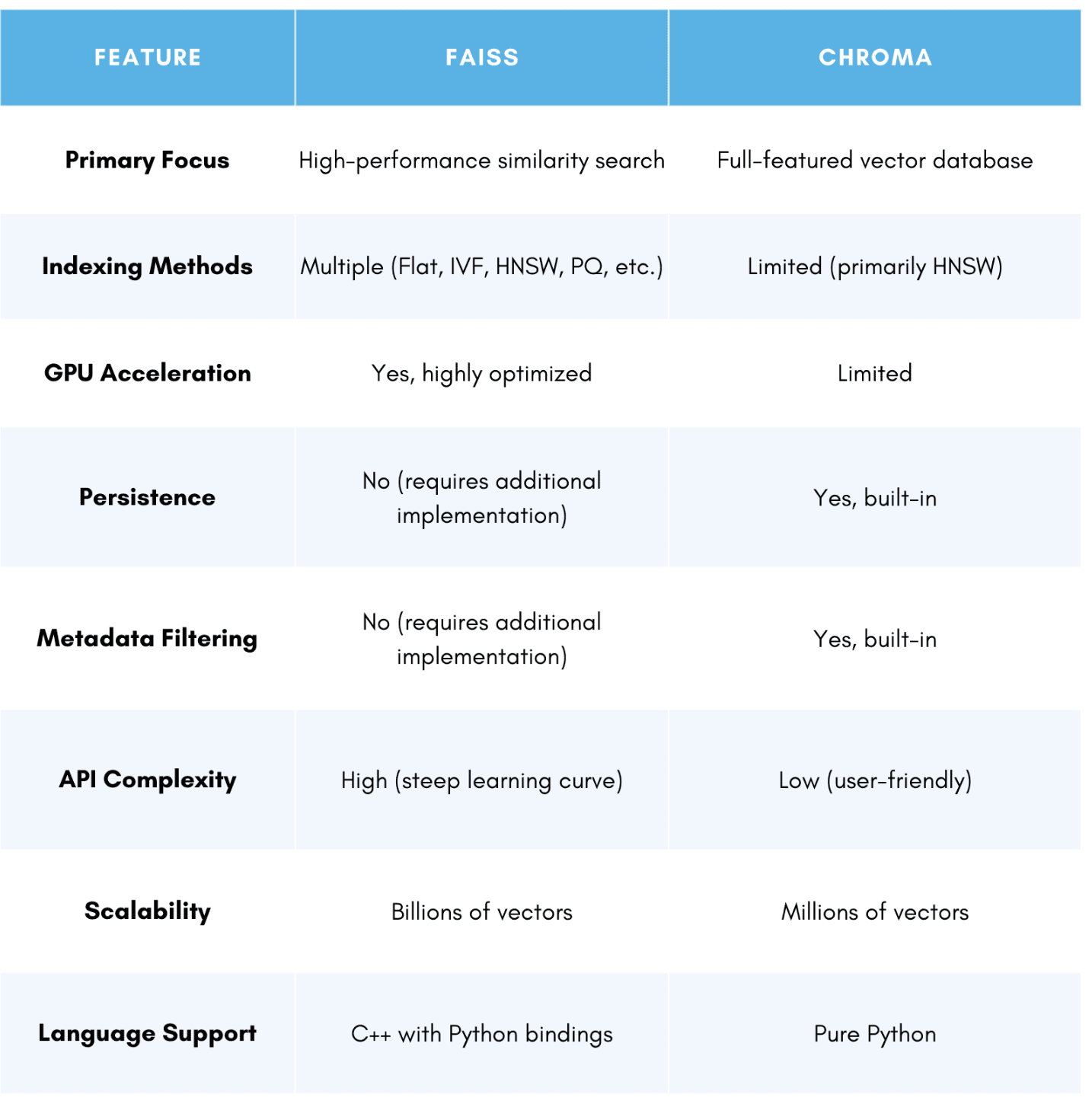
We will now be comparing two VectorDB, FAISS and ChromaDB. They represent two of the most widely used yet fundamentally different approaches to vector search. By comparing these two, we highlight the trade-offs between performance and usability, helping users understand which tool best fits their needs.
Source: Capella
FAISS (Facebook AI Similarity Search) is an open-source library developed by Facebook Research, designed for efficient similarity search and clustering of dense vector embeddings. It is wonderful for large-scale applications, supporting billion-scale vector search through advanced indexing techniques such as IVF (Inverted File Index) and HNSW (Hierarchical Navigable Small World). FAISS achieves significant performance gains using GPU acceleration, allowing rapid nearest neighbor search even on massive datasets. However, FAISS lacks built-in persistence, meaning that vectors must be stored externally in databases, requiring additional infrastructure for full-fledged applications.
Chroma, on the other hand, is a vector store and embedding database tailored for AI applications, particularly Retrieval-Augmented Generation (RAG). Unlike FAISS, Chroma provides native persistent storage, eliminating the need for external databases. It features an intuitive API that supports metadata filtering, making it easier to store, retrieve, and query embeddings with contextual information. Chroma also integrates seamlessly with popular embedding models. This makes it a practical choice for AI-driven applications that require structured metadata and efficient retrieval. However, while Chroma offers a streamlined and developer-friendly experience, it does not match FAISS’s speed and scalability for extreme-scale similarity search.
Choosing between them depends on the use case: FAISS is ideal for large-scale, high-speed similarity search with optimized indexing. Conversely, Chroma provides an all-in-one vector database solution with built-in storage and metadata filtering, making it better suited for AI-driven applications.
How Vector Databases Power Retrieval Augmented Generation (RAG)
RAG enhances large language models (LLMs) by retrieving relevant information from an external knowledge base before generating responses. Instead of relying solely on a model’s pre-trained knowledge, RAG retrieves contextually relevant documents from a VectorDB. By injecting them into the LLM’s prompt RAG improves accuracy and reduces hallucinations.
By leveraging a VectorDB, RAG enables AI models to dynamically access real-time knowledge, adapt to new information, and provide more informed, context-aware responses in applications like chatbots, search engines, and research assistants.
Videos for Further Learning
- “What is a Vector Database” from IBM Research provides a great introduction to vector databases, including its use cases (Runtime: 8 minutes).

- “Understanding Vector Databases, Explained and Compared: Pinecone, Milvus, Qdrant and FAISS” provides a great summary and comparisons of other vector databases beyond FAISS and Chroma (Runtime: 4 minutes).

Related Articles:
