Introduction
In Natural Language Processing (NLP), Language Models serve as the backbone for understanding and predicting linguistic sequences. Language Models are the next-word predictors, i.e. statistical frameworks that predict the probability of next word based on the previous words in a sequence.
N-gram models are the simplest language models that predict the probability of the next word based on the preceding N-1 words. These models provide a simple, yet effective and interpretable, methodology for language modeling.
N-grams vs. N-grams Language Model
Let’s begin by differentiating N-grams from N-grams language model.
An N-gram is a contiguous sequence of ‘n’ items. The ‘n’ specifically refers to the number of items in the sequence. These items can be phonemes, syllables, letters, words, or base pairs, depending on the application.
For example
- A 1-gram (or unigram) is a sequence of one item (e.g., a single word).
- A 2-gram (or bigram) is a sequence of two items (e.g., two consecutive words).
- A 3-gram (or trigram) is a sequence of three items, and so on.
An example explaining N-gram model

Source: AIML.com Research
An N-gram Language model is a category of probabilistic language models that predicts the probability of the next word (n-th word) in a sequence or sentence based on the occurrence of its preceding ‘n-1’ words.
This model, although less complex than its neural network counterparts, remains highly effective for pattern recognition and preliminary language structure understanding.
Types of N-gram Language Models
Unigram model: Unigram models are the simplest type of n-gram models and consider only the probability of each word’s occurrence in the corpus. They are easy to train and interpret, but they can be limited in their ability to capture the relationships between words. Unigrams are often used as a baseline for more complex n-gram models.
Bigram model: Bigram models consider the probability of pairs of words occurring together. This allows them to capture some of the relationships between words, but they can still be limited in their ability to capture longer-range dependencies. Bigram models are often used in language modeling and speech recognition.
Trigram model: Trigram models consider the probability of three words occurring together. This allows them to capture even more of the relationships between words, but they can also be more complex to train and require more data. Trigram models are often used in language translation and machine translation.
Higher n-gram models: It is possible to create n-gram models with ‘n’ greater than 3, but these models can get very complex, needing more computational resources and also requiring larger and larger datasets for calculating stable probability values. Therefore, they are rarely used in practice.
Training an N-gram model, explained using an example
Let’s consider the following example as a corpus to understand how the N-gram probabilities are computed for different N-gram models:
Corpus: “In consciousness studies the consciousness studies are fundamental”
Unigram Model:
Set of Unigrams: {“in”, “consciousness”, “studies”, “the”, “are”, “fundamental”}
The probability of a unigram w, can be estimated by taking the counts of how many times word w appears in the corpus divided by the total size of the corpus M. In the given example, M = 8
P (“consciousness”) = Count(“consciousness”) / M = 2/8
P(“are”) = Count(“are”) / M = 1 / 8, and so on.
In general, the probability of a unigram is given by:
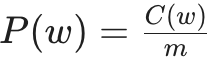
Bigrams Model:
Set of Bigrams: {‘in consciousness’, ‘consciousness studies’, ‘studies the’, ‘the consciousness’, ‘studies are’, ‘are fundamental’}
Using the example corpus above, the probability of a bigram “consciousness studies” would be the number of times the phrase “consciousness studies” occur in the corpus, divided by the count of the unigram “consciousness”. One can also think of this as the conditional probability of “studies” given that “consciousness” appeared immediately before, and is represented as follows:
P(“studies” | “consciousness”) = Count(“consciousness studies”) / Count(“consciousness”)
= 2/ 2
P(“are” | “studies”) = Count(“studies are”) / Count(“studies”) = 1/ 2
So, in general, the probability of a bigram is:
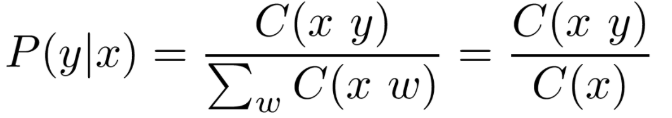
Trigrams Model:
Set of Trigrams: {‘in consciousness studies’, ‘consciousness studies the’, ‘studies the consciousness’, ‘the consciousness studies’, ‘consciousness studies are’, ‘studies are fundamental’}
In mathematical terms this will be represented as the conditional probability of the third word, given that the previous two words occurred in the text as follows:
P(“the” | “conscious studies”) = Count(“consciousness studies the”) / Count (“consciousness studies”) = 1/2
In general, the probability of a trigram is:
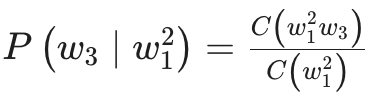
where,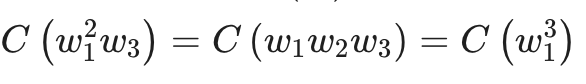
Smoothing: sequences with zero occurrence in training data
N-gram models often need help with unknown n-grams, sequences that have yet to appear in the training data. This results in zero probabilities, posing a challenge to the model’s predictive capabilities. To mitigate this, smoothing techniques like Laplace, Add-k, and Kneser-Ney are employed. Laplace smoothing adds a small constant to all n-gram counts, while Add-k uses a fractional value. Kneser-Ney smoothing, more advanced, adjusts probabilities based on the context and frequency of n-gram occurrences, ensuring more accurate and reliable predictions in the presence of unknown n-grams.
Log Probabilities
Let’s say, we want to compute the probability of the sentence in the corpus. For a bi-gram model, we can compute the probability as follows:
P(“In consciousness studies the consciousness studies are fundamental”)
= P(In | <s>) * P(consciousness | In) * P(studies | consciousness) * P(the | studies) * P(consciousness | the) * P(studies | consciousness) * P(are | studies) * P(fundamental | are) * P(</s> | fundamental)
As you can see, the probability of the sentence is a product of multiple probabilities. Multiplying small numbers like these can result in numerical underflow. We can make this more numerically stable by taking log on both sides of the equation:
log P(“In consciousness studies the consciousness studies are fundamental“)
= log P(In | <s>) + log P(consciousness | In) + log P(studies | consciousness) + log P(the | studies) + log P(consciousness | the) + log P(studies | consciousness) + log P(are | studies) + log P(fundamental | are) + log P (</s> | fundamental)
Log transformation like this will convert the product of small numbers to a sum of small numbers, thereby making the computation more stable
Evaluating N-gram models: Perplexity
Perplexity is a metric used in language modeling to evaluate how well a model predicts a sample of text. It tells us if a text resembles something written by a human or if it seems more like a random selection of words. Human-written text typically has lower perplexity, indicating a more predictable and coherent structure, while randomly generated text has higher perplexity due to its unpredictable nature.
Given a sequence of words, Perplexity is calculated as follows:
Perplexity(sequence) = P(w1w2…wn)-1/n
Perplexity(sequence) = P(w1|<s>) * P(w2|w1) * … * P(wn|wn-1) for a bigram model
Since Perplexity is inversely proportional to the probability of the sequence, lower value of the Perplexity means higher probability of the sentence. Lower the value of Perplexity, better is the probability of the sequence. Instead of multiplying probability values, we can take log on both sides to calculate Log perplexity as negative average of the sum of n-gram log probabilities.
Applications of n-gram models in Language Processing
- Text generation: N-gram models can predict the next word in a sentence, given the previous n-1 words. This is useful for tasks such as autocomplete and text generation.
- Speech recognition: N-gram models can be used to recognize spoken words, by predicting the most likely sequence of words that could have produced the speech signal.
- Language translation: N-gram models can be used to translate text from one language to another, by predicting the most likely sequence of words in the target language that corresponds to the sequence of words in the source language.
Conclusion
In conclusion, N-gram models are a vital tool in natural language processing, offering a balance between computational simplicity and linguistic context. While they effectively capture language patterns and assist in various applications, they also face challenges like unknown n-grams, data sparsity, and difficulty in capturing long-range dependencies.
Video Explanation
- In this video titled “NLP: Understanding the N-gram language models”, Anna Potapenko explains succinctly the concept of language model, types of n-gram models, training process and its applications. Very clearly explained and easy to follow (Runtime: 10 mins)

- In this video titled “Language Model Evaluation and Perplexity”, the educator explains the methodology of how to evaluate a language model using unigram, bigram, and trigram language models as examples. Both these videos together will give you a good understanding of the various aspects of n-gram models. (Runtime: 6 mins)

Contributions
Written By: Pradeep Das, Software Engineer (ML, Recommendation Systems, NLP) @ Amazon
Edited By: AIML Research Team
