
Source: Wikimedia Commons
What is Computer Vision?
Computer vision refers to the extraction of information from visual data, in the form of predictions, identification, captioning, and more. It encompasses any task that involves image, video, and other signal data, and can be modified from the 2D case to 3D and temporal data. Healthcare, defense, and several other industries actively apply computer vision. From diagnostic tools to facial recognition, it appears in tools of many forms and use cases.
Computer vision as a field stems from traditional image processing approaches. Image processing involves the use of mathematical techniques to enhance or transform images. It can also be used to derive analytics from images, and tends to favor a more rigid mathematical approach compared to fluid approaches such as those taken by machine learning.
If we look at the image processing supercategory, we can split this into 4 main tasks:
- Image acquisition and representation
- Image transformations
- Image translation to parameters
- Parameter translation to decisions
Computer Vision is concerned with tasks 3 and 4: taking images from their innate data to a parameterized representations through machine learning methods, then using these parameterizations to definitively generate outputs. These can range from classification labels and text captions, to new images.
Computer Vision Pipeline
In practice, the computer vision pipeline encompasses the following pipeline:

Source: AIML.com Research
- Data collection – Regardless of whether the data is collected specifically for a task or sourced from a publicly available dataset, it must align with the requirements of the intended task. For example, a supervised approach may require the dataset to include labels or probability atlases.
- Preprocessing – Data may require cleaning to remove NaN values, outliers, and other inconsistencies.
- Feature extraction – Approaches such as PCA, Chi-square tests, and Lasso regression reduce data dimensionality. Additionally, SIFT, SURF, HOG and more provide methods to represent the data in feature spaces with fewer dimensions.
- ML/AI approaches – Depending on the problem, different architectures succeed at parameterizing the problem. Reference “History of Computer Vision” for examples.
- Output/decision metrics – In this step, the parameterized architecture assigns labels, identifies probability, or predicts future values. This may involve multiple steps, which many AI/ML approaches encapsulate.
- Analysis/explainability – Good models do not behave like black boxes. Developing robust solutions involves clearly visualizing and representing the effect of individual features, architecture choices. Some common visual techniques include GradCAM, as well as modified SHAP and xAI.
Common Computer Vision Tasks
| Task | Description | Commonly used models |
| Image Classification | Assign a label to images | LeNet, AlexNet, ResNet |
| Object Detection | Identify objects by type and location | YOLO, R-CNN |
| Image Segmentation | Separate image into parts | UNet, ResNet, Mask R-CNN |
| Facial Recognition | Identify individuals based on features | VGGFace, DeepFace |
| Optical Character Recognition | Recognize content of handwritten or typed text | CRNN, Tesseract |
| Image Captioning | Assign descriptions to images | Show and Tell, Image Transformers, Reinforcement Learning |
| Visual Question Answering | Use images to answer text queries | Vision Language Transformers |
| Image Retrieval | Use images to query a database | SIFT, CNNs |
| Image Generation | Create new images based on expectation set | GANs |
| Pose and Motion Estimation | Describe future events using indications in image structure | Mask R-CNN, PoseFlow |
| 3D Reconstruction | Stitch 2D slices or timepoints into a higher dimension representation | SLAM, SfM, Depth Estimation |
Image Classification
In image classification, the goal is to assign labels to images, such as “cat” or “dog”. MNIST, CIFAR, and ImageNet are some of the most popular datasets to train these tasks. Many industries demonstrate this, with Google Search implementing lightweight classification algorithms to improve search results.
Object Detection
This is an expansion upon image classification, additionally identifying the locations of the object within the image. Surveillance systems or automated vehicles often employ object detection techniques.
Image Segmentation
This task involves breaking up an image into partitions. This can be used to identify contours, sections of an object, or just simplify the “gray levels” within an image. Medical imaging often relies on segmentation to separate anatomical components.
Facial Recognition
This is an expansion of image classification, where there are unique identifiers for each individual; rather than identifying multiple cats with the same label “cat”, the same label “Person X” will only be applied to images of Person X that may appear from different angles, not every person. Facial recognition systems can be seen in smartphones, airport security systems, and more.
Optical Character Recognition
OCR refers to the “reading” of images of text. Just as the human brain can identify the letter “d” regardless of font or handwriting style, OCR aims to be stylistically blind. It is often used in document digitization.
Image Captioning
Generating captions for images, and by extension video, necessitates a deeper understanding not only of the objects within the frame, but their relationships to other objects. Transformer based models often receive this task, as seen in automatic captioning and report generation.
Visual Question Answering
An extension of captioning, VQA allows textual input from the user alongside the image data. Vision Language Models generate textual responses, building off object detection, classification, and relationship recognition approaches. This can be seen in some chatbots and medical diagnostic software.
Image Retrieval
This task involves querying a database using images or text. Images can be stored in their feature representations so a query which highlights certain features is able to evaluate larger databases for close matches quickly. A prime example of this is Google and other browsers’ image search.
Image Generation
Generation unlocks the predictive capability of computer vision models. Often utilizing GAN networks, or even diffusion models, image generation seeks to understand the distributions within images of interest, and generate new images that fall within the same distributions. It can be heavily driven by Bayesian statistics, or traditional ML approaches to fine tune stochastic generations. This can be seen in synthetic data generation, art style transfers, and even image editing softwares.
Pose and Motion Estimation
Estimating structural features of images such as position, orientation, arrangement, and more to understand static and dynamic scenes. Athletic analyses, gesture-based recognition and navigation systems all employ these techniques.
3D Reconstruction
A 3d structure represents a physical object or its evolution in time using 2D slices or timepoints. It is a highly important problem in healthcare and virtual twin modeling, but can also be found in many industries that study historical evolution or structures only visible under particular imaging protocols.
History of Computer Vision
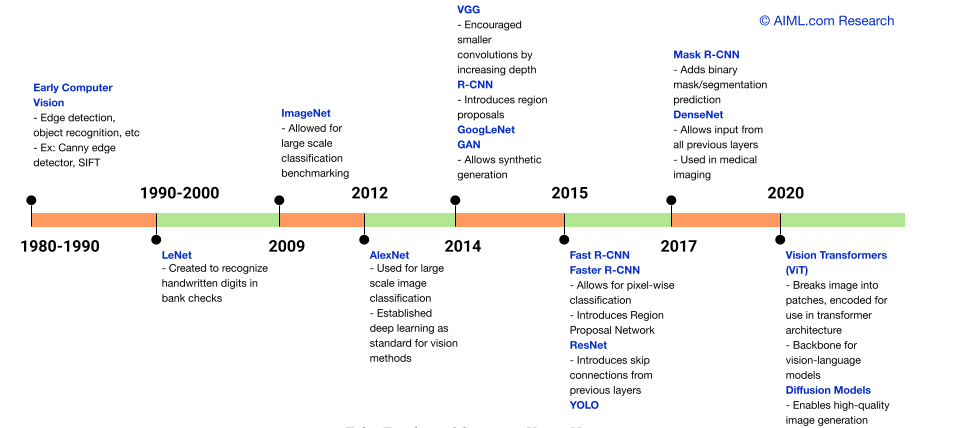
Source: AIML.com Research
Related Papers:
- LeNet: Gradient-based learning applied to document recognition
- AlexNet: ImageNet Classification with Deep Convolutional Neural Networks
- VGG: Very Deep Convolutional Networks for Large-Scale Image Recognition
- GoogleNet: Going Deeper with Convolutions
- R-CNN: Rich feature hierarchies for accurate object detection and semantic segmentation
- Fast R-CNN: Fast R-CNN
- Faster R-CNN: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- Mask R-CNN: Mask R-CNN
- ResNet: Deep Residual Learning for Image Recognition
- YOLO: You Only Look Once: Unified, Real-Time Object Detection
- DenseNet: Densely Connected Convolutional Networks
- Vision Transformers: An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale
Commonly Used Datasets
| Dataset | Description | Typical tasks | Image Specifications |
| ImageNet | Wide variety of images, most generalizable | Image Classification | 14M images, 21000 categories |
| CIFAR | Wide variety of images of size 32×32, often used for benchmarking | Image Classification | 60000 images, 10 categories (CIFAR-10) or 100 categories (CIFAR-100) |
| MNIST | Handwritten digits | Optical Character Recognition | 70000 images, 10 categories |
| COCO | Objects presented within several contexts | Object Detection, Image Segmentation, Image Captioning | 330000 images, 80 categories, 1.5M object instances |
| Pascal VOC | Objects labeled with bounding boxes, pixel-wise classification | Object Detection, Image Segmentation | 10000 images, 20 categories |
| LFW | Facial recognition dataset | Facial Recognition | 13000 images, 5749 individuals |
What are some typical challenges in computer vision?
Listed below are some of the challenges one might face when working with computer vision tasks:
Data Complexity and Ambiguity
The complexity of perception and the ambiguity in how images are interpreted can hinder vision tasks. For example, human vision relies heavily on repeated exposure to visual instances to learn, and the same is true of computers. Most commonly, researchers find challenge in the sheer lack of the high volume data required by visual training. Many publicly available datasets address this problem, but they often remain too general and provide insufficient context, especially in cases such as medical diagnostics. The quality of data is also immensely important, as this can affect the model’s accuracy and sensitivity to noise and other aberrations.
Runtime Considerations
Another constant pursuit in vision is runtime efficiency. Adding more layers and approaches such as region proposals can lead to large improvements in accuracy, but also require more computational time and resources.
Lack of Generalizability
Models are also highly personalized to the tasks they are trained for, and often struggle when applied to similar problems in different contexts. Transfer learning and zero-shot prediction work to target these problems.
Beyond the Model
Most importantly, vision is always subject to ethical and open-source concerns. It is always important to evaluate the long-standing effect of vision solutions, and how both privacy and bias-free learning are integral to their success. Watch the videos below to see how privacy and fairness are taken into consideration as computer vision solutions are developed.
Video Explanations:
- In this “Eye on AI” episode, Alice Xiang speaks on privacy and fairness challenges involved in vision systems, such as ethical and technical issues. Watch to see some proposed solutions (Runtime: 42 mins)

- This video titled “How to Avoid Bias in Computer Vision Models” by Roboflow details how to identify and address biases within computer vision systems, highlighting approaches such as data first mentality, active learning, and model error analysis. (Runtime: 29 mins)

Related Questions:
