Multi-Head Attention
Multi-head attention extends the idea of single-head attention by running multiple attention heads in parallel on the same input sequence. This lets the model learn various relationships and patterns in the input data simultaneously. It greatly boosts the model’s expressive power compared to using a single attention head.
Related Question: Explain Attention, and Masked Self-Attention as used in Transformers
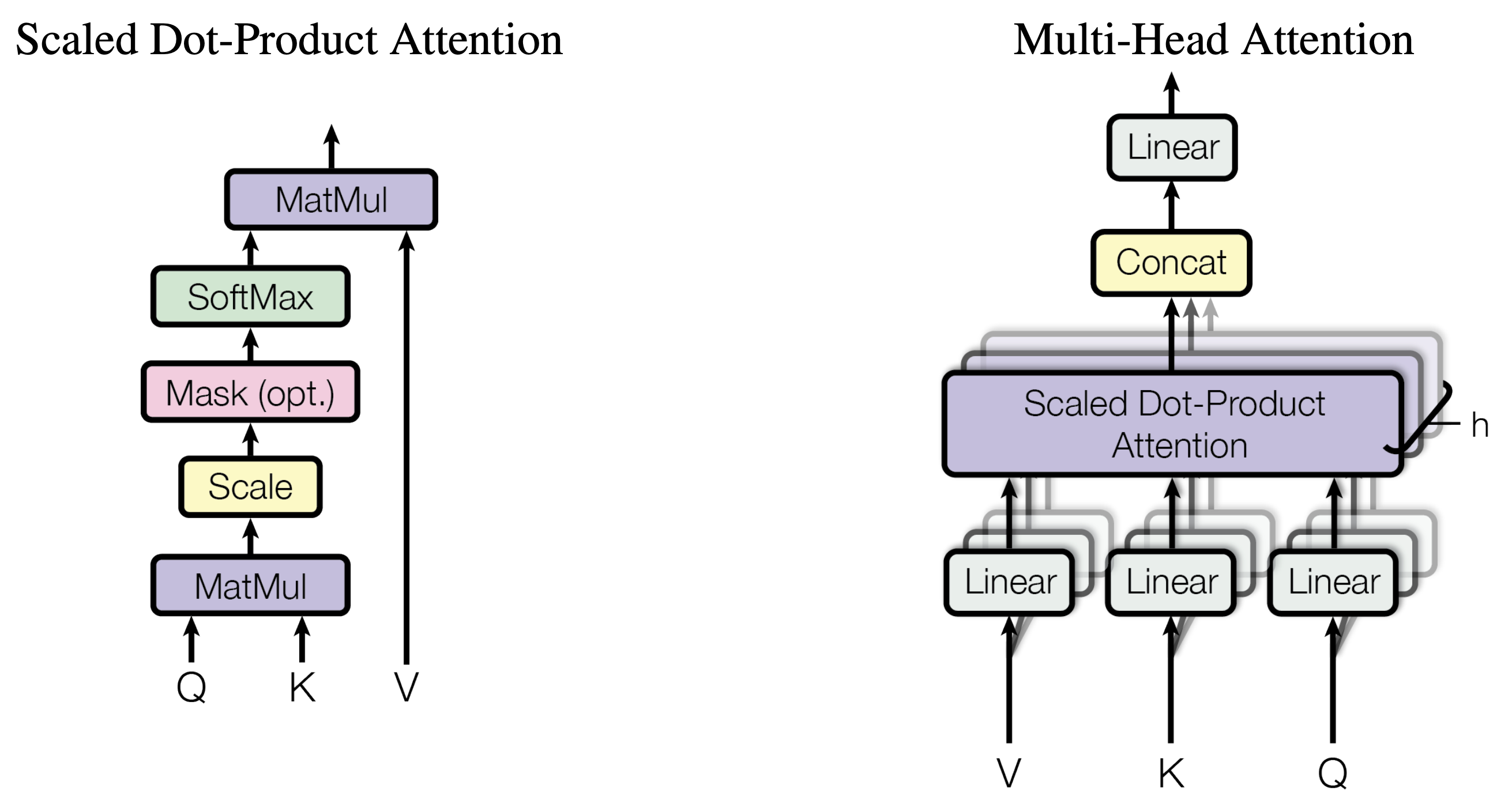
(right) Multi-Head Attention consists of several attention layers running in parallel
Source: Attention is all you need (2017)
Implementation of Multi-Head Attention
- Instead of having a single set of learnable K, Q, and V matrices, multiple sets are initialized (one for each attention head)
- Each attention head independently computes attention scores and produces its own attention weighted output.
- Outputs from all heads are concatenated and linearly transformed to form the final multi-head attention output.
- Each attention head targets different input parts, capturing diverse patterns and relationships in the data.
Benefits and Limitations of Multi-Head Attention over Single-Head Attention
– Increased Expressiveness: Multi-head attention captures diverse dependencies and patterns simultaneously. This is key to understanding complex relationships in data.
– Improved Generalization: By learning multiple sets of attention parameters, the model becomes more robust and adaptable to different tasks and datasets.
– Increased Computational Complexity: Multi-head attention enhances the model’s capabilities. However, it also increases computational complexity, requiring more compute resources. To help mitigate this, during inference time, a mechanism called Head Pruning is employed to discard heads that are less useful.
Related Questions:
– Explain Self-Attention, and Masked Self-Attention as used in Transformers
– What are transformers? Discuss the major breakthroughs in transformer models
– Explain the Transformer Architecture
