Source: neo4j
Introduction
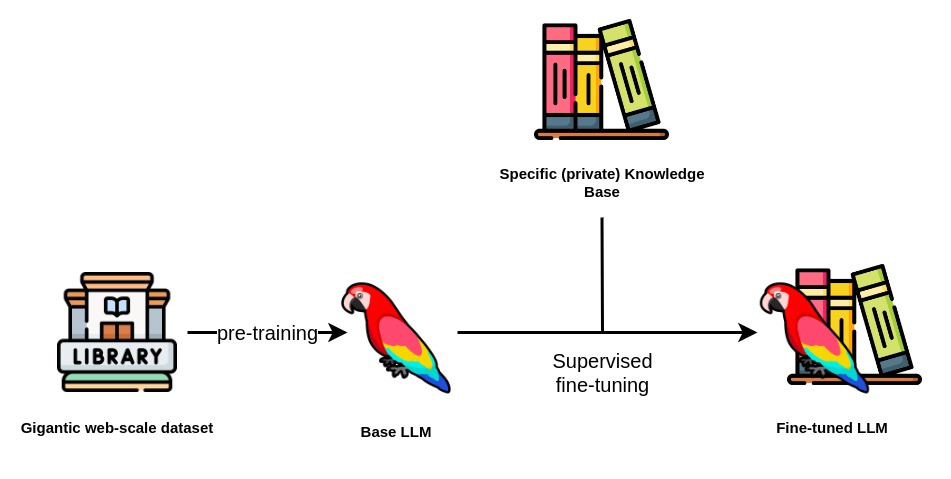
Supervised Fine-Tuning (SFT) refers to the process of adapting a pre-trained base model to specific tasks using labeled data. By leveraging supervised fine-tuning, the fine-tuned model achieves enhanced performance on the target task, demonstrating a deeper understanding of task-specific nuances and requirements. To understand supervised fine-tuning, it’s helpful to first learn about pre-trained base models and transfer learning.
Pre-trained Base Models?
Pre-training typically involves training base models on large datasets to help them learn general representations. Researchers train language models like BERT and GPT on massive corpora to capture general language patterns. BERT uses masked language modeling (MLM) and next sentence prediction (NSP) objectives during pre-training, while GPT learns through autoregressive next-token prediction. Through pre-training on large-scale data, these models develop a sophisticated understanding of general language patterns. However, they often struggle with specialized domains where relevant content is scarce in their pre-training data.
Transfer Learning
One of the primary challenges in deploying large models is the scarcity of labeled data for specific tasks. Transfer learning offers a promising solution to this challenge by adapting pre-trained models. Researchers train these models on vast datasets, such as millions of Wikipedia articles and books, and then fine-tune them for specific downstream tasks using relatively small amounts of task-specific data, often just a few thousand examples. Transfer learning encompasses various adaptation approaches, including both supervised and unsupervised methods, making it a broader concept than supervised fine-tuning.
Supervised Fine-tuning
The term “supervised” reflects the use of labeled data, where the dataset creator pairs each input with a corresponding ground truth output or label. During fine-tuning, the model calculates the loss between its predictions and the ground truth. The optimization algorithm then uses this loss to update the model’s parameters through backpropagation, refining its performance on the task.
The following diagram shows the supervised fine-tuning procedure:
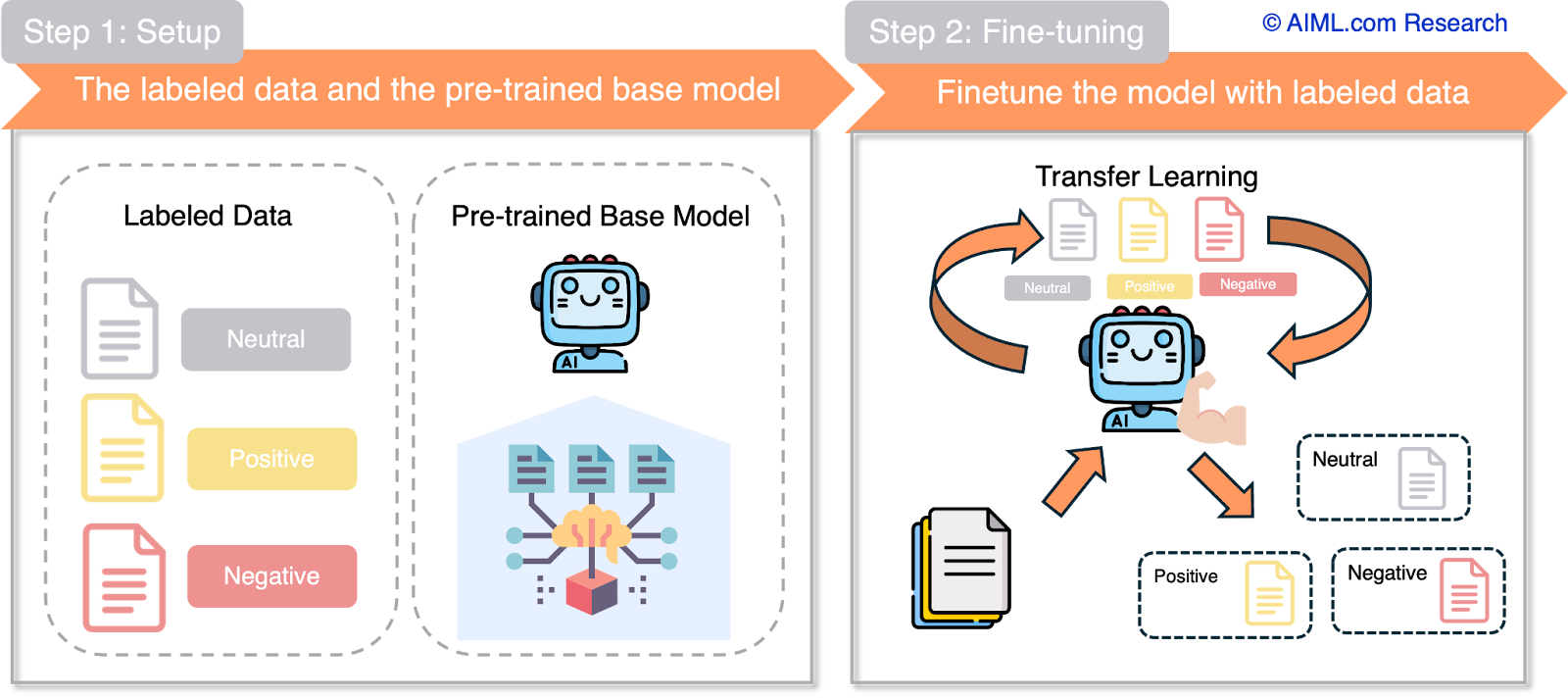
Source: AIML.com Research
Examples of the Labeled Dataset
The format of labeled datasets can vary depending on the specific task requirements. Here are some examples of labeled datasets:
- Text classification: {“text”: “I love this movie!”, “label”: “positive”}
- Image classification: {“image”: “dog.jpg”, “label”: “dog”}
- Sequence-to-sequence tasks: {“input”: “Translate this to French”, “output”: “Traduisez cela en français”}
Fine-Tuning Techniques
Be Cautious of Overfitting and Catastrophic Forgetting
Two significant challenges arise during model fine-tuning: overfitting and catastrophic forgetting. Overfitting occurs when the model becomes too specialized to the fine-tuning dataset, learning specific patterns that don’t generalize well to unseen data. The issue of catastrophic forgetting is that the model loses much of its pre-trained general knowledge while adapting to the new task. Forgetting occurs when the model loses much of its pre-trained general knowledge while adapting to the new task. During fine-tuning, the optimization process drastically modifies the model parameters, causing it to “forget” valuable representations it learned during pre-training.
Finetuning Strategies
Several techniques have been used in supervised fine-tuning:
- Finetuning the added layers: The most conservative approach is to freeze all base model weights and train only the added task-specific layers. This preserves the pre-trained knowledge while allowing adaptation to new tasks through the added layers.
- Partial Fine-tuning: freezing the initial layers of the base model while fine-tuning the later layers that has more association with specific tasks.
- Full Fine-tuning: finetuning all layers of the parameters. While this approach offers maximum flexibility, using too many training epochs can lead to catastrophic forgetting. Thus this strategy typically requires careful learning rate selection and early stopping to maintain a balance between adaptation and preservation of general knowledge.
Applications
Supervised Fine-Tuning is commonly used in different forms of tasks. Here are some scenarios of its usage.
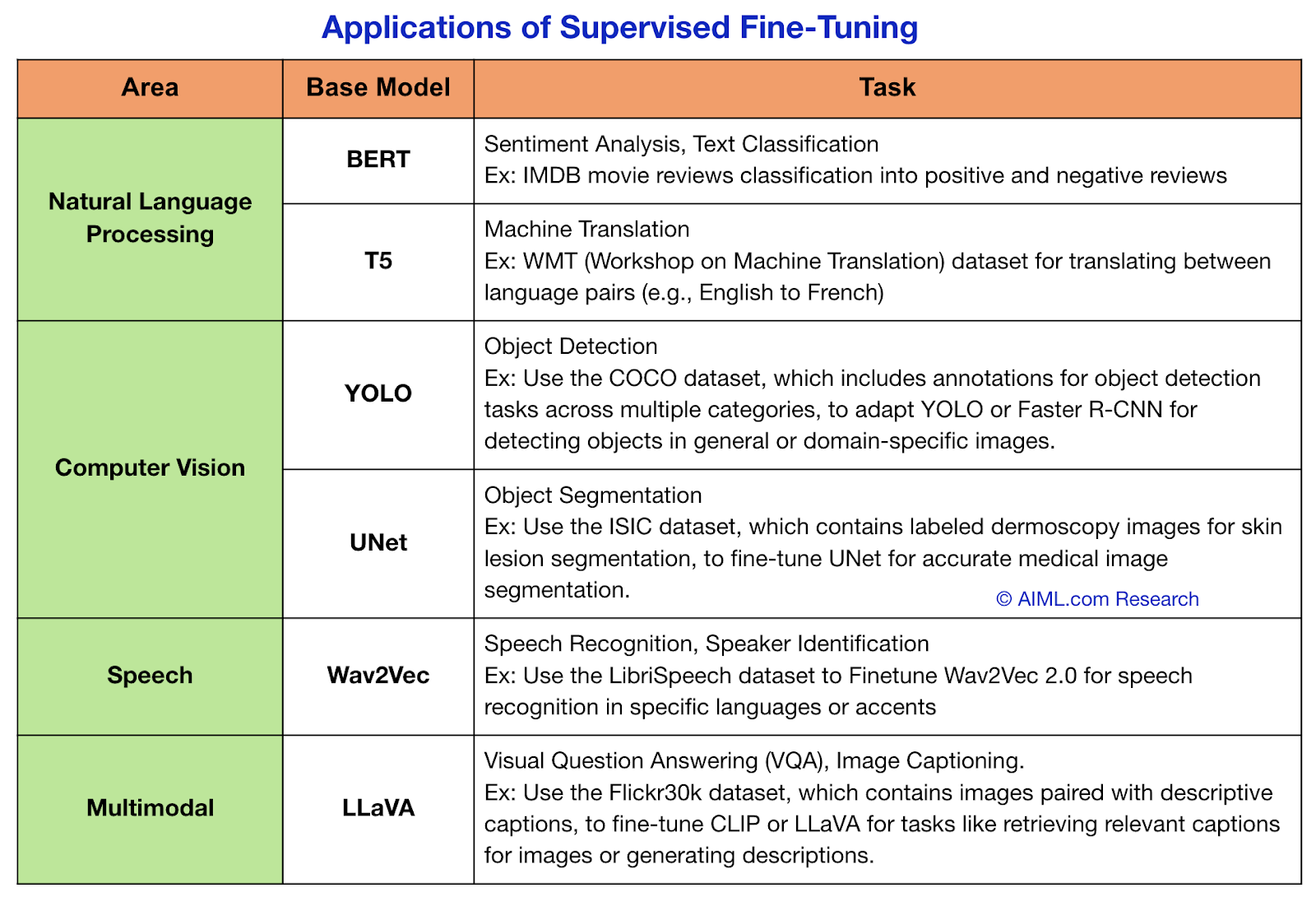
Source: AIML.com Research
How is Supervised Fine-tuning different from Instruction Fine-tuning
The instruction fine-tuning (IFT) also uses labeled data. However, the difference between supervised fine tuning and instruction fine-tuning is that the latter focuses more on a variety of instruction-output pairs (e.g., “Classify the sentiment of ‘Great movie!'” → “The sentiment is positive”), while the former one typically uses simple input-output pairs (e.g., sentiment classification: “Great movie!” → “Positive”). As a result, models after SFT learn to perform specific tasks but may not understand the broader context, while models after IFT learn to interpret instructions and respond appropriately, more like a conversational agent.
Video Explanation
- In this video, Oren Sultan discusses the concept of fine-tuning and compares it with prompt engineering and the RAG method.

- The video by SuperDataScienceWithJonKrohn gives a brief introduction to what supervised fine-tuning is:

- In Stanford’s CS229N course, Building Large Language Models (LLMs), the professor discusses supervised fine-tuning in large language models starting at 1:02:30 in the video. It covers the impact of large-scale data on the performance of language models:https://www.youtube.com/watch?v=9vM4p9NN0Ts
Notebook Tutorial
A notebook tutorial showcasing a simple example of supervised fine-tuning of a large language model for the task of summary generation.
Related Questions:
